Для разбиения отдельного pdf документа на страницы воспользуемся следующей программой
#
from PyPDF2 import PdfFileReader, PdfFileWriter
pdf_document = "D:\Надя\Костерин\Поддомены\source\Формула включений и исключений.pdf"
pdf = PdfFileReader(pdf_document)
for page in range(pdf.getNumPages()):
pdf_writer = PdfFileWriter()
current_page = pdf.getPage(page)
pdf_writer.addPage(current_page)
outputFilename = "dist/Форм_вкл_искл-page-{}.pdf".format(page + 1)
with open(outputFilename, "wb") as out:
pdf_writer.write(out)
print("created", outputFilename)
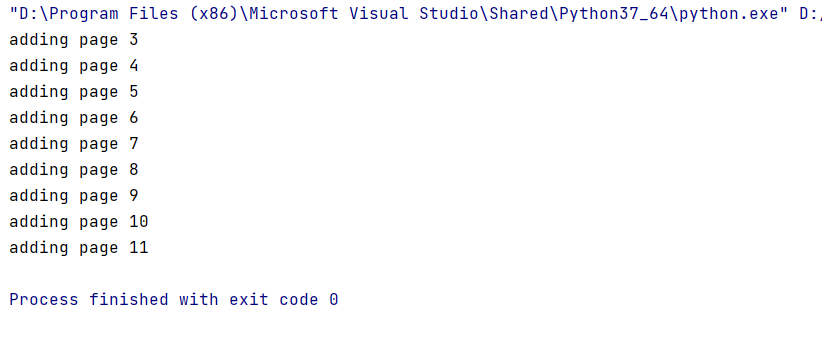
Результат представлен на следующем рисунке
Найти все страницы, где есть заданный текст
#
import fitz
filename = "D:\Надя\Костерин\Поддомены\source\Формула включений и исключений.pdf"
search_term = "множество"
pdf_document = fitz.open(filename)
for current_page in range(len(pdf_document)):
page = pdf_document.loadPage(current_page)
if page.searchFor(search_term):
print("%s найдено на странице %i" % (search_term, current_page+1))
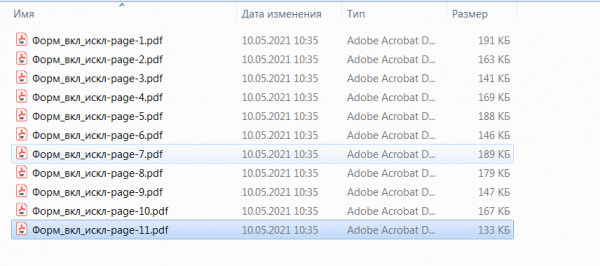
Осуществим поиск в документе Формула включения и исключения.pdf слова «множество».
Результат работы программы представлен ниже.
Добавление водяного знака с помощью PyPDF2
Добавим в pdf файл водяной знак «Черновик». Текст программы
#
# Добавление водяного знака в одностраничный PDF
import PyPDF2
input_file = "D:\Надя\Костерин\Поддомены\source\Задание 12.3.pdf"
output_file = "dist/Водяной_знак-page-drafted.pdf"
watermark_file = "source/Черновик.pdf"
with open(input_file, "rb") as filehandle_input:
# читать содержимое исходного файла
pdf = PyPDF2.PdfFileReader(filehandle_input)
with open(watermark_file, "rb") as filehandle_watermark:
# читать содержание водяного знака
watermark = PyPDF2.PdfFileReader(filehandle_watermark)
# получить первую страницу оригинального PDF
first_page = pdf.getPage(0)
# получить первую страницу водяного знака PDF
first_page_watermark = watermark.getPage(0)
# объединить две страницы
first_page.mergePage(first_page_watermark)
# создать объект записи PDF для выходного файла
pdf_writer = PyPDF2.PdfFileWriter()
# добавить страницу
pdf_writer.addPage(first_page)
with open(output_file, "wb") as filehandle_output:
# записать файл с водяными знаками в новый файл
pdf_writer.write(filehandle_output)
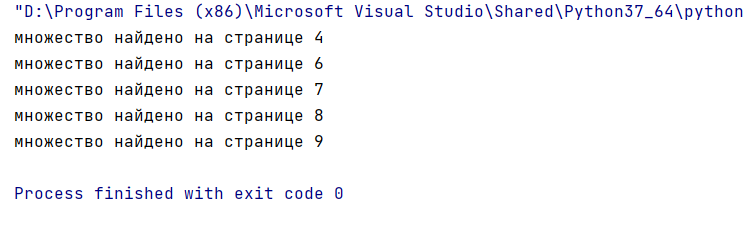
Результат работы программы

Удаление страниц с помощью pdfrw
Для удаления страниц необходимо установить библиотеку pdfrw. Текст программы приведен ниже.
#
# Удалите первые две страницы (титульный лист) из PDF
from pdfrw import PdfReader, PdfWriter
input_file = "D:\Надя\Костерин\Поддомены\source\Формула включений и исключений.pdf"
output_file = "dist/Удаление_страниц-page-drafted.pdf"
# Определить объекты чтения и записи
reader_input = PdfReader(input_file)
writer_output = PdfWriter()
# Перейти на страницу один за другим
for current_page in range(len(reader_input.pages)):
if current_page > 1:
writer_output.addpage(reader_input.pages[current_page])
print("adding page %i" % (current_page + 1))
# Записать измененный контент на диск
writer_output.write(output_file)
Результат работы программы – сформирован новый файл, у которого вырезано 2 первые страницы.