Bokeh - библиотека для интерактивной визуализации данных. Он отображает графику с помощью HTML и JavaScript. Что делает его удобным для создания веб-панелей и приложений.
#
# Библиотеки Bokeh
from bokeh.io import output_file
from bokeh.plotting import figure, show
# Рисунок будет отображен в статическом HTML-файле с именем output_file_test.html
output_file('output_file_test.html',
title='Empty Bokeh Figure')
# Настроить общий объект figure()
fig = figure()
# Посмотрите, как это выглядит
show(fig)
Результат работы программы:

Рисование данных с помощью глифов
#
# Библиотеки Bokeh
from bokeh.io import output_file
from bokeh.plotting import figure, show
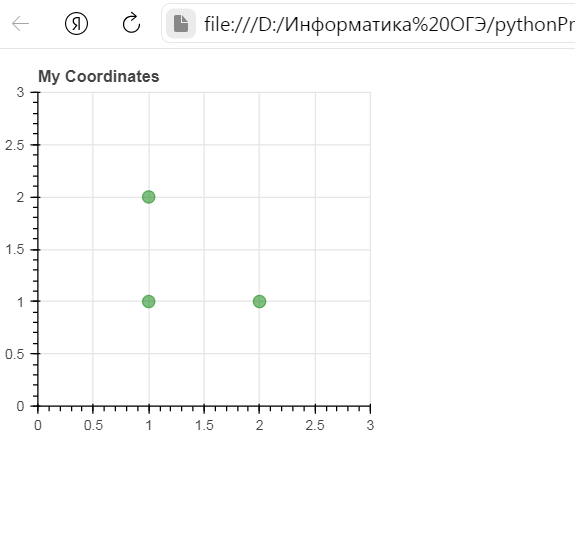
# Мои данные о координатах x-y
x = [1, 2, 1]
y = [1, 1, 2]
# Рисунок будет отображен в статическом HTML-файле с именем output_file_test.html
output_file('output_file_test.html',
title='Empty Bokeh Figure')
# Настроить общий объект figure()
fig = figure(title='My Coordinates',
plot_height=300, plot_width=300,
x_range=(0, 3), y_range=(0, 3),
toolbar_location=None)
# Нарисуйте координаты в виде кругов
fig.circle(x=x, y=y,
color='green', size=10, alpha=0.5)
# Показать сюжет
show(fig)
Результат работы программы:
Программный код.
#
# Библиотеки Bokeh
from bokeh.io import output_file
from bokeh.plotting import figure, show
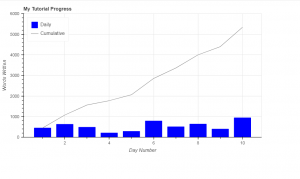
# Мои данные о подсчете слов
day_num = np.linspace(1, 10, 10)
daily_words = [450, 628, 488, 210, 287, 791, 508, 639, 397, 943]
cumulative_words = np.cumsum(daily_words)
# Рисунок будет отображен в статическом HTML-файле с именем output_file_test.html
output_file('output_file_test.html',
title='Empty Bokeh Figure')
# Создаем фигуру с осью x типа datetime
fig = figure(title='My Tutorial Progress',
plot_height=400, plot_width=700,
x_axis_label='Day Number', y_axis_label='Words Written',
x_minor_ticks=2, y_range=(0, 6000),
toolbar_location=None)
# Ежедневные слова будут представлены в виде вертикальных полос (столбцов)
fig.vbar(x=day_num, bottom=0, top=daily_words,
color='blue', width=0.75,
legend='Daily')
# Накопленная сумма будет линией тренда
fig.line(x=day_num, y=cumulative_words,
color='gray', line_width=1,
legend='Cumulative')
# Поместите легенду в левый верхний угол
fig.legend.location = 'top_left'
# Давайте проверим
show(fig)
Результат работы программы: