В первой части этой серии вы использовали Flask и Connexion для создания REST API, обеспечивающего операции CRUD для простой структуры в памяти, называемой PEOPLE. Это помогло продемонстрировать, как модуль Connexion помогает вам создавать хороший REST API вместе с интерактивной документацией.
Как отмечалось в комментариях к части 1, структура PEOPLE переинициализируется каждый раз при перезапуске приложения. В этой статье вы узнаете, как сохранить структуру PEOPLE и действия, которые API предоставляет, для базы данных с использованием SQLAlchemy и Marshmallow.
SQLAlchemy предоставляет объектно-реляционную модель (ORM), которая хранит объекты Python для представления данных объекта в базе данных. Это может помочь вам продолжать мыслить на Pythonic и не беспокоиться о том, как данные объекта будут представлены в базе данных.
Marshmallow обеспечивает функциональность для сериализации и десериализации объектов Python по мере их поступления в наш REST API на основе JSON. Marshmallow преобразует экземпляры класса Python в объекты, которые можно преобразовать в JSON.
Вы можете найти код Python для этой статьи здесь.
Для Кого Предназначена Эта Статья
Если вам понравилась часть 1 этой серии, эта статья еще больше расширяет ваш пояс для инструментов. Вы будете использовать SQLAlchemy для доступа к базе данных более Pythonic, чем прямой SQL. Вы также будете использовать Marshmallow для сериализации и десериализации данных, управляемых REST API. Для этого вы будете использовать основные функции объектно-ориентированного программирования, доступные в Python.
Вы также будете использовать SQLAlchemy для создания базы данных и взаимодействия с ней. Это необходимо для того, чтобы REST API работал и работал с данными PEOPLE, использованными в части 1.
Веб-приложение, представленное в части 1, будет иметь небольшие изменения в файлах HTML и JavaScript для поддержки изменений. Вы можете ознакомиться с окончательной версией кода из части 1 здесь.
Дополнительная зависимость
Прежде чем приступить к созданию этой новой функциональности, вам необходимо обновить virtualenv. Вы создали его для выполнения кода части 1 или для создания нового кода для этого проекта. Самый простой способ сделать это после активации virtualenv-выполнить эту команду:
pip install Flask-SQLAlchemy flask-marshmallow marshmallow-sqlalchemy marshmallow
Это добавляет дополнительную функциональность в ваш virtualenv:
- Flask-SQLAlchemy добавляет SQLAlchemy, а также некоторые привязки к Flask, что позволяет программам получать доступ к базам данных.
- flask-marshmallow добавляет части Flask к Marshmallow, что позволяет программам конвертировать объекты Python в сериализуемые структуры и обратно.
- marshmallow-sqlalchemy добавляет некоторые хуки marshmallow в SQLAlchemy, чтобы позволить программам сериализовать и десериализовать объекты Python, созданные SQLAlchemy.
- marshmallow добавляет основную часть функциональности marshmallow.
Данные PEOPLE
Как уже упоминалось выше, структура данных PEOPLE в предыдущей статье является словарем Python. В этом словаре вы использовали фамилию человека в качестве ключа поиска. Структура данных выглядела примерно так:
# Data to serve with our API
PEOPLE = {
"Farrell": {
"fname": "Doug",
"lname": "Farrell",
"timestamp": get_timestamp()
},
"Brockman": {
"fname": "Kent",
"lname": "Brockman",
"timestamp": get_timestamp()
},
"Easter": {
"fname": "Bunny",
"lname": "Easter",
"timestamp": get_timestamp()
}
}
Изменения, которые вы внесете в программу, переместят все данные в таблицу базы данных. Это означает, что данные будут сохранены на вашем диске и будут существовать между запусками server.py.
Поскольку фамилия была ключом словаря, код ограничивал изменение фамилии человека: только имя может быть изменено. Кроме того, перемещение в базу данных позволит вам изменить фамилию, поскольку она больше не будет использоваться в качестве ключа поиска для человека.
Концептуально таблицу базы данных можно рассматривать как двумерный массив, в котором строки являются записями, а столбцы-полями в этих записях.
Таблицы базы данных обычно имеют автоинкрементное целочисленное значение в качестве ключа поиска для строк. Это называется первичным ключом. Каждая запись в таблице будет иметь первичный ключ, значение которого уникально во всей таблице. Наличие первичного ключа, независимого от данных, хранящихся в таблице, освобождает вас для изменения любого другого поля в строке.
Примечание:
Автоинкрементирующий первичный ключ означает, что база данных берет на себя заботу:
- Приращение самого большого существующего поля первичного ключа каждый раз, когда в таблицу вставляется новая запись
- Использование этого значения в качестве первичного ключа для новых вставленных данных
Это гарантирует уникальный первичный ключ по мере роста таблицы.
Вы будете следовать соглашению с базой данных, называя таблицу как единственную, поэтому таблица будет называться person. Перевод приведенной выше структуры PEOPLE в таблицу базы данных с именем person дает вам следующее:
| person_id | lname | fname | timestamp |
|---|---|---|---|
| 1 | Farrell | Doug | 2018-08-08 21:16:01.888444 |
| 2 | Brockman | Kent | 2018-08-08 21:16:01.889060 |
| 3 | Easter | Bunny | 2018-08-08 21:16:01.886834 |
Описание столбцов таблицы:
- person_id: поле первичного ключа для каждого пользователя
- lname: фамилия этого человека
- fname: имя этого человека
- timestamp: метка времени, связанная с действиями вставки / обновления
Взаимодействие С Базой Данных
Мы будем использовать SQLite как компонент database engine для хранения PEOPLE. SQLite является наиболее широко распространенной базой данных в мире, и он поставляется с Python бесплатно. Он быстр, выполняет всю свою работу с использованием файлов и подходит для очень многих проектов. Это полная СУБД (система управления реляционными базами данных), которая включает в себя SQL, язык многих систем баз данных.
На данный момент, отобразим person
В отличие от языков программирования, таких как Python, SQL не определяет, как получить данные: он описывает, какие данные нужны, оставляя "как" до ядра СУБД.
SQL-запрос, получающий все данные в person таблице, отсортированные по фамилии, будет выглядеть вот так:
SELECT * FROM person ORDER BY 'lname';
Этот запрос сообщает ядру базы данных, что нужно получить все поля из таблицы person и отсортировать их по умолчанию в порядке возрастания, используя lname.
Если мы выполним этот запрос к базе данных SQLite, содержащей person таблица,то результаты будут представлять собой набор записей, содержащих все строки в таблице, причем каждая строка содержит данные из всех полей, составляющих строку. Ниже приведен пример использования инструмента командной строки SQLite, выполняющего указанный выше запрос к person:
sqlite> SELECT * FROM person ORDER BY lname; 2|Brockman|Kent|2018-08-08 21:16:01.888444 3|Easter|Bunny|2018-08-08 21:16:01.889060 1|Farrell|Doug|2018-08-08 21:16:01.886834
Вывод выше представляет собой список всех строк в person
Python полностью способен взаимодействовать со многими механизмами баз данных и выполнять SQL-запрос, описанный выше. Результатом, скорее всего, будет список кортежей. Внешний список содержит все записи в person. Каждый отдельный внутренний кортеж будет содержать все данные, представляющие каждое поле, определенное для строки таблицы.
Получение данных таким способом не очень питоническое. Список записей в порядке, но каждая отдельная запись - это просто набор данных. Программа должна знать индекс каждого поля, чтобы получить конкретное поле. Следующий код Python использует SQLite, чтобы продемонстрировать, как выполнить вышеуказанный запрос и отобразить данные:
import sqlite3
conn = sqlite3.connect('people.db')
cur = conn.cursor()
cur.execute('SELECT * FROM person ORDER BY lname')
people = cur.fetchall()
for person in people:
print(f'{person[2]} {person[1]}')
Программа выше делает следующее:
- Строка 1 импортирует sqlite3 модуль.
- Строка 3 создает соединение с файлом базы данных.
- Строка 4 создает курсор.
- Строка 5 использует курсор для выполнения SQL запроса, выраженного в виде строки.
- Строка 6 получает все записи, возвращаемые SQL запросом, и присваивает их переменной people.
- Строки 7 и 8 перебирают переменную people и выводят имя и фамилию каждого человека.
Переменная people из строки 6 выше будет выглядеть в Python следующим образом:
people = [
(2, 'Brockman', 'Kent', '2018-08-08 21:16:01.888444'),
(3, 'Easter', 'Bunny', '2018-08-08 21:16:01.889060'),
(1, 'Farrell', 'Doug', '2018-08-08 21:16:01.886834')
]
Вывод программы выше выглядит следующим образом:
Kent Brockman Bunny Easter Doug Farrell
В приведенной выше программе вы должны знать, что имя человека в индексе 2, а фамилия человека в индексе 1. Хуже того, внутренняя структура person должна также быть известна всякий раз, когда вы передаете переменную итерации person в качестве параметра функции или методу.
Было бы намного лучше, если бы вы получили объект person Python, где каждое из полей является атрибутом объекта. Это одна из вещей, которая делает SQLAlchemy.
Маленькие Таблицы Бобби
В приведенной выше программе оператор SQL представляет собой простую строку, передаваемую непосредственно в базу данных для выполнения. В этом случае это не проблема, потому что SQL является строковым литералом, полностью находящимся под контролем программы. Однако сценарий использования вашего REST API будет принимать пользовательский ввод из веб-приложения и использовать его для создания запросов SQL. Это может открыть ваше приложение для атаки.
Из первой части вы помните, что REST API для получения одного person от PEOPLE выглядело так:
GET /api/people/{lname}
Это означает, что ваш API ожидает переменную, lname в пути к конечной точке URL, который используется для поиска person. Изменение кода Python SQLite сверху для этого будет выглядеть примерно так:
lname = 'Farrell'
cur.execute('SELECT * FROM person WHERE lname = \'{}\''.format(lname))
Приведенный выше фрагмент кода выполняет следующие действия:
- Строка 1 устанавливает переменную lname в 'Farrell'. Это будет происходить из пути к конечной точке URL REST API.
- Строка 2 использует форматирование строки Python для создания строки SQL и ее выполнения.
Для простоты приведенный выше код устанавливает переменную lname в константу, но на самом деле она будет исходить из пути конечной точки URL-адреса API и может быть любой, предоставленной пользователем. SQL запрос, сгенерированный форматированием строки, выглядит так:
SELECT * FROM person WHERE lname = 'Farrell'
Когда этот SQL выполняется базой данных, он ищет в таблице персонала запись, в которой фамилия равна «Farrell». Это то, что нужно, но любая программа, которая принимает пользовательский ввод, также открыта для злоумышленников. В вышеприведенной программе, где переменная lname задается введенным пользователем вводом, это открывает для вашей программы так называемую SQL-инъекцию. Это то, что ласково называют «Маленькими таблицами Бобби»:
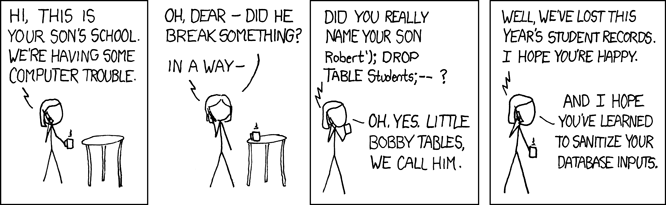
Например, представьте, что злонамеренный пользователь назвал ваш REST API следующим образом:
GET /api/people/Farrell');DROP TABLE person;
Приведенный выше запрос REST API устанавливает для переменной lname значение «Farrell»); DROP TABLE person; ', что в приведенном выше коде сгенерирует этот оператор SQL:
SELECT * FROM person WHERE lname = 'Farrell');DROP TABLE person;
Приведенный выше оператор SQL действителен, и при выполнении базой данных он найдет одну запись, где lname соответствует «Farrell». Затем он найдет символ разделителя оператора SQL; и пойдет прямо вперед и уронит весь стол. Это по существу разрушило бы ваше приложение.
Вы можете защитить свою программу, очистив все данные, которые вы получаете от пользователей вашего приложения. Очистка данных в этом контексте означает, что ваша программа должна проверить предоставленные пользователем данные и убедиться, что они не содержат ничего опасного для программы. Это может быть сложно сделать правильно и должно быть сделано везде, где пользовательские данные взаимодействуют с базой данных.
Есть еще один способ, который намного проще: использовать SQLAlchemy. Он будет очищать пользовательские данные перед созданием операторов SQL. Это еще одно большое преимущество и причина использовать SQLAlchemy при работе с базами данных.
Моделирование данных с помощью SQLAlchemy
SQLAlchemy - это большой проект, который предоставляет множество функций для работы с базами данных с использованием Python. Одна из вещей, которую он предоставляет, - это ORM, или Object Relational Mapper, и это то, что вы собираетесь использовать для создания и работы с таблицей базы данных person. Это позволяет сопоставить строку полей из таблицы базы данных с объектом Python.
Объектно-ориентированное программирование позволяет связывать данные вместе с поведением, функциями, которые работают с этими данными. Создав классы SQLAlchemy, вы можете связать поля из строк таблицы базы данных с поведением, позволяя вам взаимодействовать с данными. Вот определение класса SQLAlchemy для данных в таблице базы данных person:
class Person(db.Model):
__tablename__ = 'person'
person_id = db.Column(db.Integer,
primary_key=True)
lname = db.Column(db.String)
fname = db.Column(db.String)
timestamp = db.Column(db.DateTime,
default=datetime.utcnow,
onupdate=datetime.utcnow)
Класс Person наследуется от db.Model, который вы получите, когда начнете создавать программный код. На данный момент это означает, что вы наследуете от базового класса Model, предоставляя атрибуты и функциональные возможности, общие для всех производных классов.
Остальные определения являются атрибутами уровня класса, определенными следующим образом:
- __tablename__ = 'person' связывает определение класса с таблицей базы данных person.
- person_id = db.Column (db.Integer, primary_key = True) создает столбец базы данных, содержащий целое число, выступающее в качестве первичного ключа для таблицы. Это также сообщает базе данных, что person_id будет автоинкрементным целочисленным значением.
- lname = db.Column (db.String) создает поле фамилии, столбец базы данных, содержащий строковое значение.
- fname = db.Column (db.String) создает поле первого имени, столбец базы данных, содержащий строковое значение.
- timestamp = db.Column (db.DateTime, default = datetime.utcnow, onupdate = datetime.utcnow) создает поле отметки времени, столбец базы данных, содержащий значение даты / времени. Параметр default = datetime.utcnow по умолчанию устанавливает значение метки времени до текущего значения utcnow при создании записи. Параметр onupdate = datetime.utcnow обновляет отметку времени с использованием текущего значения utcnow при обновлении записи.
Примечание: метки времени UTC
Вам может быть интересно, почему метка времени в вышеприведенном классе по умолчанию используется и обновляется методом datetime.utcnow (), который возвращает UTC или всемирное координированное время. Это способ стандартизации источника вашей метки времени.
Источником, или нулевым временем, является линия, проходящая с севера на юг от севера до южного полюса Земли через Великобританию. Это нулевой часовой пояс, от которого смещены все остальные часовые пояса. Используя его в качестве источника нулевого времени, ваши временные метки будут смещены относительно этой стандартной контрольной точки.
Если к вашему приложению обращаются из разных часовых поясов, у вас есть способ выполнить вычисления даты / времени. Все, что вам нужно, это метка времени UTC и часовой пояс пункта назначения.
Если бы вы использовали местные часовые пояса в качестве источника меток времени, то вы не могли бы выполнять вычисления даты / времени без информации о смещении часовых поясов по местному времени от нуля. Без информации об источнике отметки времени вы вообще не могли бы сравнивать дату / время или выполнять математические операции.
Работа с временными метками на основе UTC является хорошим стандартом для подражания. Вот сайт с инструментарием для работы и лучшего понимания.
Куда вы направляетесь с этим определением класса Person? Конечная цель - иметь возможность выполнить запрос с использованием SQLAlchemy и получить список экземпляров класса Person. В качестве примера давайте рассмотрим предыдущий оператор SQL:
SELECT * FROM people ORDER BY lname;
Покажите ту же небольшую примерную программу сверху, но теперь с использованием SQLAlchemy:
from models import Person
people = Person.query.order_by(Person.lname).all()
for person in people:
print(f'{person.fname} {person.lname}')
На данный момент, игнорируя строку 1, вам нужны все записи о людях, отсортированные в порядке возрастания по полю lname. Что вы получаете от операторов SQLAlchemy Person.query.order_by (Person.lname) .all () - это список объектов Person для всех записей в таблице базы данных person в указанном порядке. В приведенной выше программе переменная people содержит список объектов Person.
Программа перебирает переменную people, беря каждого человека по очереди и распечатывая имя и фамилию человека из базы данных. Обратите внимание, что программе не нужно использовать индексы для получения значений fname или lname: она использует атрибуты, определенные в объекте Person.
Использование SQLAlchemy позволяет вам мыслить с точки зрения объектов с поведением, а не необработанного SQL. Это становится еще более полезным, когда ваши таблицы базы данных становятся больше и взаимодействие становится более сложным.
Сериализация / десериализация смоделированных данных
Работа со смоделированными данными SQLAlchemy внутри ваших программ очень удобна. Это особенно удобно в программах, которые манипулируют данными, возможно, делают расчеты или используют их для создания презентаций на экране. Ваше приложение представляет собой REST API, по существу обеспечивающее операции CRUD с данными, и поэтому оно не выполняет значительных манипуляций с данными.
API REST работает с данными JSON, и здесь вы можете столкнуться с проблемой модели SQLAlchemy. Поскольку данные, возвращаемые SQLAlchemy, являются экземплярами класса Python, Connexion не может сериализовать эти экземпляры класса в данные в формате JSON. Помните из части 1, что Connexion - это инструмент, который вы использовали для разработки и настройки REST API с использованием файла YAML, и подключения к нему методов Python.
В этом контексте сериализация означает преобразование объектов Python, которые могут содержать другие объекты Python и сложные типы данных, в более простые структуры данных, которые могут быть проанализированы в типы данных JSON, которые перечислены здесь:
- string: строка
- number: числа, поддерживаемые Python (целые числа, числа с плавающей точкой, длинные)
- object: объект JSON, который примерно эквивалентен словарю Python
- array: примерно эквивалентен списку Python
- boolean: представлен в JSON как true или false, но в Python как True или False
- null: по сути, None в Python
Например, ваш класс Person содержит метку времени, которая представляет собой Python DateTime. В JSON отсутствует определение даты / времени, поэтому временную метку необходимо преобразовать в строку, чтобы она существовала в структуре JSON.
Ваш класс Person достаточно прост, поэтому получение атрибутов данных из него и создание словаря для возврата из конечных точек REST URL не составит большого труда. В более сложном приложении со многими более крупными моделями SQLAlchemy это было бы не так. Лучшее решение - использовать модуль Marshmallow, чтобы сделать эту работу за вас.
Marshmallow помогает вам создать класс PersonSchema, который похож на класс PersonAchechemy Person, который мы создали. Здесь, однако, вместо сопоставления таблиц базы данных и имен полей с классом и его атрибутами, класс PersonSchema определяет, как атрибуты класса будут преобразованы в дружественные JSON форматы. Вот определение класса Зефир для данных в нашей таблице персонала:
class PersonSchema(ma.ModelSchema):
class Meta:
model = Person
sqla_session = db.session
Класс PersonSchema наследуется от ma.ModelSchema, который вы получите, когда начнете создавать программный код. На данный момент это означает, что PersonSchema наследуется от базового класса Marshmallow под названием ModelSchema, предоставляя атрибуты и функциональные возможности, общие для всех производных классов.
Остальная часть определения выглядит следующим образом:
- класс Meta определяет класс с именем Meta в вашем классе. Класс ModelSchema, от которого наследуется класс PersonSchema, ищет этот внутренний мета-класс и использует его для поиска в модели SQLAlchemy Person и db.session. Вот как Marshmallow находит атрибуты в классе Person и тип этих атрибутов, поэтому он знает, как их сериализовать / десериализовать.
- model модель сообщает классу, какую модель SQLAlchemy использовать для сериализации / десериализации данных в и из.
- db.session сообщает классу, какой сеанс базы данных использовать для анализа и определения типов данных атрибута.
Куда вы направляетесь с этим определением класса? Вы хотите иметь возможность сериализовать экземпляр класса Person в данные JSON, а также десериализовать данные JSON и создать из них экземпляры класса Person.
Создание инициализированной базы данных
SQLAlchemy обрабатывает многие взаимодействия, характерные для конкретных баз данных, и позволяет вам сосредоточиться на моделях данных, а также на том, как их использовать.
Теперь, когда вы на самом деле собираетесь создать базу данных, как уже упоминалось ранее, вы будете использовать SQLite. Вы делаете это по нескольким причинам. Он поставляется с Python и не должен быть установлен как отдельный модуль. Он сохраняет всю информацию базы данных в одном файле и поэтому прост в настройке и использовании.
Установка отдельного сервера базы данных, такого как MySQL или PostgreSQL, будет работать нормально, но для этого потребуется установить эти системы и запустить их в работу, что выходит за рамки этой статьи.
Поскольку SQLAlchemy управляет базой данных, во многих отношениях действительно не имеет значения, что является базовой базой данных.
Вы собираетесь создать новую служебную программу под названием build_database.py для создания и инициализации файла базы данных SQLite people.db, содержащего вашу таблицу базы данных person. Попутно вы создадите два модуля Python, config.py и models.py, которые будут использоваться build_database.py и измененным server.py из части 1.
Здесь вы можете найти исходный код для модулей, которые вы собираетесь создать, которые представлены здесь:
- config.py получает необходимые модули, импортированные в программу и настроенные. Это включает в себя Flask, Connexion, SQLAlchemy и Marshmallow. Поскольку он будет использоваться как build_database.py, так и server.py, некоторые части конфигурации будут применяться только к приложению server.py.
- models.py - это модуль, в котором вы создадите определения классов Person SQLAlchemy и PersonSchema Marshmallow, описанные выше. Этот модуль зависит от config.py для некоторых объектов, созданных и настроенных там.
Модуль config
Модуль config.py, как следует из названия, - это место, где вся информация о конфигурации создается и инициализируется. Мы собираемся использовать этот модуль как для нашего файла программы build_database.py, так и для скорого обновления файла server.py из статьи части 1. Это означает, что мы собираемся настроить Flask, Connexion, SQLAlchemy и Marshmallow здесь.
Хотя программа build_database.py не использует Flask, Connexion или Marshmallow, она использует SQLAlchemy для создания нашего соединения с базой данных SQLite. Вот код для модуля config.py:
import os import connexion from flask_sqlalchemy import SQLAlchemy from flask_marshmallow import Marshmallow basedir = os.path.abspath(os.path.dirname(__file__)) # Create the Connexion application instance connex_app = connexion.App(__name__, specification_dir=basedir) # Get the underlying Flask app instance app = connex_app.app # Configure the SQLAlchemy part of the app instance app.config['SQLALCHEMY_ECHO'] = True app.config['SQLALCHEMY_DATABASE_URI'] = 'sqlite:////' + os.path.join(basedir, 'people.db') app.config['SQLALCHEMY_TRACK_MODIFICATIONS'] = False # Create the SQLAlchemy db instance db = SQLAlchemy(app) # Initialize Marshmallow ma = Marshmallow(app)
Вот что делает приведенный выше код:
- Строки 2 - 4 импортируют Connexion, как вы это делали в программе server.py из части 1. Он также импортирует SQLAlchemy из модуля flask_sqlalchemy. Это дает доступ к базе данных вашей программы. Наконец, он импортирует Marshmallow из модуля flask_marshamllow.
- В строке 6 создается переменная basedir, указывающая на каталог, в котором запущена программа.
- В строке 9 используется переменная basedir для создания экземпляра приложения Connexion и указания ему пути к файлу swagger.yml.
- Строка 12 создает переменную app, которая является экземпляром Flask, инициализированным Connexion.
- Строки 15 используют переменную приложения для настройки значений, используемых SQLAlchemy. Сначала он устанавливает SQLALCHEMY_ECHO в True. Это заставляет SQLAlchemy выводить операторы SQL, которые он выполняет, на консоль. Это очень полезно для устранения проблем при создании программ баз данных. Установите значение False для производственных сред.
- Строка 16 устанавливает SQLALCHEMY_DATABASE_URI в sqlite: //// '+ os.path.join (basedir,' people.db '). Это говорит SQLAlchemy использовать SQLite в качестве базы данных и файл с именем people.db в текущем каталоге в качестве файла базы данных. Различные движки баз данных, такие как MySQL и PostgreSQL, будут иметь разные строки SQLALCHEMY_DATABASE_URI для их настройки.
- Строка 17 устанавливает для SQLALCHEMY_TRACK_MODIFICATIONS значение False, отключая систему событий SQLAlchemy, которая включена по умолчанию. Система событий генерирует события, полезные в программах, управляемых событиями, но добавляет значительные накладные расходы. Поскольку вы не создаете программу, управляемую событиями, отключите эту функцию.
- Строка 19 создает переменную db, вызывая SQLAlchemy (приложение). Это инициализирует SQLAlchemy путем передачи только что установленной информации о конфигурации приложения. Переменная db - это то, что импортируется в программу build_database.py, чтобы предоставить ей доступ к SQLAlchemy и базе данных. Он будет служить той же цели в программе server.py и модуле people.py.
- Строка 23 создает переменную ma, вызывая Marshmallow (app). Это инициализирует Marshmallow и позволяет ему анализировать компоненты SQLAlchemy, прикрепленные к приложению. Вот почему Marshmallow инициализируется после SQLAlchemy.
Модуль Models
Модуль models.py создан для предоставления классов Person и PersonSchema в точности так, как описано в разделах выше о моделировании и сериализации данных. Вот код для этого модуля:
from datetime import datetime
from config import db, ma
class Person(db.Model):
__tablename__ = 'person'
person_id = db.Column(db.Integer, primary_key=True)
lname = db.Column(db.String(32), index=True)
fname = db.Column(db.String(32))
timestamp = db.Column(db.DateTime, default=datetime.utcnow, onupdate=datetime.utcnow)
class PersonSchema(ma.ModelSchema):
class Meta:
model = Person
sqla_session = db.session
Вот что делает приведенный выше код:
- Строка 1 импортирует объект datetime из модуля datetime, поставляемого с Python. Это дает вам возможность создать метку времени в классе Person.
- В строке 2 импортируются переменные экземпляра db и ma, определенные в модуле config.py. Это дает модулю доступ к атрибутам и методам SQLAlchemy, связанным с переменной db, а также к атрибутам и методам Marshmallow, связанным с переменной ma.
- Строки 4-9 определяют класс Person, как обсуждалось в разделе моделирования данных выше, но теперь вы знаете, откуда берется db.Model, который наследует класс. Это дает функции класса SQLAlchemy класса Person, такие как подключение к базе данных и доступ к ее таблицам.
- Строки 11 - 14 определяют класс PersonSchema, как обсуждалось в разделе сериализации данных выше. Этот класс наследует от ma.ModelSchema и предоставляет функции Marshmallow класса PersonSchema, такие как интроспекция класса Person, чтобы помочь сериализовать / десериализовать экземпляры этого класса.
Создание базы данных
Вы видели, как таблицы базы данных могут быть сопоставлены с классами SQLAlchemy. Теперь используйте то, что вы узнали, чтобы создать базу данных и заполнить ее данными. Вы собираетесь создать небольшую служебную программу для создания и создания базы данных с данными People. Вот программа build_database.py:
import os
from config import db
from models import Person
# Data to initialize database with
PEOPLE = [
{'fname': 'Doug', 'lname': 'Farrell'},
{'fname': 'Kent', 'lname': 'Brockman'},
{'fname': 'Bunny','lname': 'Easter'}
]
# Delete database file if it exists currently
if os.path.exists('people.db'):
os.remove('people.db')
# Create the database
db.create_all()
# Iterate over the PEOPLE structure and populate the database
for person in PEOPLE:
p = Person(lname=person['lname'], fname=person['fname'])
db.session.add(p)
db.session.commit()
Вот что делает приведенный выше код:
- Строка 2 импортирует экземпляр db из модуля config.py.
- Строка 3 импортирует определение класса Person из модуля models.py.
- Строки 6-10 создают структуру данных PEOPLE, которая представляет собой список словарей, содержащих ваши данные. Структура была сокращена для экономии места для презентации.
- Строки 13 и 14 выполняют некоторые простые действия по удалению файла people.db, если он существует. В этом файле хранится база данных SQLite. Если вам когда-нибудь придется заново инициализировать базу данных, чтобы начать все сначала, это гарантирует, что вы начинаете с нуля при создании базы данных.
- Строка 17 создает базу данных с помощью вызова db.create_all (). Это создает базу данных с использованием экземпляра db, импортированного из модуля config. Экземпляр базы данных - это наше соединение с базой данных.
- Строки 20 - 22 перебирают список PEOPLE и используют словари для создания экземпляра класса Person. После его создания вы вызываете функцию db.session.add (p). При этом для доступа к объекту сеанса используется экземпляр подключения к базе данных. Сеанс - это то, что управляет действиями базы данных, которые записываются в сеансе. В этом случае вы выполняете метод add (p), чтобы добавить новый экземпляр Person в объект сеанса.
- Строка 24 вызывает db.session.commit () для фактического сохранения всех созданных объектов-людей в базе данных.
Примечание. В строке 22 данные не были добавлены в базу данных. Все сохраняется в объекте сеанса. Только когда вы выполняете вызов db.session.commit () в строке 24, сеанс взаимодействует с базой данных и фиксирует действия для нее.
В SQLAlchemy сеанс является важным объектом. Он действует как канал связи между базой данных и объектами Python SQLAlchemy, созданными в программе. Сеанс помогает поддерживать согласованность между данными в программе и теми же данными, которые существуют в базе данных. Он сохраняет все действия с базой данных и соответственно обновляет базовую базу данных как явными, так и неявными действиями, предпринимаемыми программой.
Теперь вы готовы запустить программу build_database.py для создания и инициализации новой базы данных. Вы делаете это с помощью следующей команды, когда ваша виртуальная среда Python активна:
python build_database.py
Когда программа запускается, она выводит сообщения журнала SQLAlchemy на консоль. Это результат установки SQLALCHEMY_ECHO в True в файле config.py. Многое из того, что регистрирует SQLAlchemy, это команды SQL, которые он генерирует для создания и построения файла базы данных SQLite people.db. Вот пример того, что выводится при запуске программы:
2018-09-11 22:20:29,951 INFO sqlalchemy.engine.base.Engine SELECT CAST('test plain returns' AS VARCHAR(60)) AS anon_1
2018-09-11 22:20:29,951 INFO sqlalchemy.engine.base.Engine ()
2018-09-11 22:20:29,952 INFO sqlalchemy.engine.base.Engine SELECT CAST('test unicode returns' AS VARCHAR(60)) AS anon_1
2018-09-11 22:20:29,952 INFO sqlalchemy.engine.base.Engine ()
2018-09-11 22:20:29,956 INFO sqlalchemy.engine.base.Engine PRAGMA table_info("person")
2018-09-11 22:20:29,956 INFO sqlalchemy.engine.base.Engine ()
2018-09-11 22:20:29,959 INFO sqlalchemy.engine.base.Engine
CREATE TABLE person (
person_id INTEGER NOT NULL,
lname VARCHAR,
fname VARCHAR,
timestamp DATETIME,
PRIMARY KEY (person_id)
)
2018-09-11 22:20:29,959 INFO sqlalchemy.engine.base.Engine ()
2018-09-11 22:20:29,975 INFO sqlalchemy.engine.base.Engine COMMIT
2018-09-11 22:20:29,980 INFO sqlalchemy.engine.base.Engine BEGIN (implicit)
2018-09-11 22:20:29,983 INFO sqlalchemy.engine.base.Engine INSERT INTO person (lname, fname, timestamp) VALUES (?, ?, ?)
2018-09-11 22:20:29,983 INFO sqlalchemy.engine.base.Engine ('Farrell', 'Doug', '2018-09-12 02:20:29.983143')
2018-09-11 22:20:29,984 INFO sqlalchemy.engine.base.Engine INSERT INTO person (lname, fname, timestamp) VALUES (?, ?, ?)
2018-09-11 22:20:29,985 INFO sqlalchemy.engine.base.Engine ('Brockman', 'Kent', '2018-09-12 02:20:29.984821')
2018-09-11 22:20:29,985 INFO sqlalchemy.engine.base.Engine INSERT INTO person (lname, fname, timestamp) VALUES (?, ?, ?)
2018-09-11 22:20:29,985 INFO sqlalchemy.engine.base.Engine ('Easter', 'Bunny', '2018-09-12 02:20:29.985462')
2018-09-11 22:20:29,986 INFO sqlalchemy.engine.base.Engine COMMIT
Использование базы данных
Как только база данных будет создана, вы можете изменить существующий код из части 1, чтобы использовать ее. Все необходимые изменения связаны с созданием значения первичного ключа person_id в нашей базе данных в качестве уникального идентификатора, а не значения lname.
Обновление API REST
Ни одно из изменений не является очень существенным, и вы начнете с переопределения REST API. В приведенном ниже списке показано определение API из части 1, но оно обновлено для использования переменной person_id в пути URL:
| Действие | http-глагол | url-путь | Описание |
|---|---|---|---|
| Создание | post | /api/people | определяет уникальный url для создания нового человека |
| Чтение | get | /api/people | определяет уникальный url для чтения коллекции людей |
| Чтение | get | /api/people/{person_id} | определяет уникальный url для чтения конкретного человека по person_id |
| Обновление | put | /api/people/{person_id} | определяет уникальный url для обновления существующего человека по person_id |
| Удаление | delete | /api/orders/{person_id} | определяет уникальный url для удаления существующего человека по person_id |
В тех случаях, когда для определения URL-адреса требовалось значение lname, теперь им требуется идентификатор person_id (первичный ключ) для записи о человеке в таблице сотрудников. Это позволяет вам удалить код в предыдущем приложении, который искусственно ограничивал пользователей от редактирования фамилии человека.
Для того, чтобы вы могли реализовать эти изменения, файл swagger.yml из части 1 необходимо будет отредактировать. По большей части любое значение параметра lname будет изменено на person_id, а person_id будет добавлен в ответы POST и PUT. Вы можете проверить обновленный файл swagger.yml.
Обновление обработчиков API REST
После обновления файла swagger.yml для поддержки использования идентификатора person_id вам также потребуется обновить обработчики в файле people.py для поддержки этих изменений. Точно так же, как файл swagger.yml был обновлен, вам нужно изменить файл people.py, чтобы использовать значение person_id вместо lname.
Вот часть обновленного модуля person.py, показывающая обработчик для конечной точки URL-адреса REST GET / api / people:
from flask import (
make_response,
abort,
)
from config import db
from models import (
Person,
PersonSchema,
)
def read_all():
"""
This function responds to a request for /api/people
with the complete lists of people
:return: json string of list of people
"""
# Create the list of people from our data
people = Person.query \
.order_by(Person.lname) \
.all()
# Serialize the data for the response
person_schema = PersonSchema(many=True)
return person_schema.dump(people).data
Вот что делает приведенный выше код:
- Строки 1 - 9 импортируют некоторые модули Flask для создания ответов REST API, а также импортируют экземпляр db из модуля config.py. Кроме того, он импортирует классы SQLAlchemy Person и Marshmallow PersonSchema для доступа к таблице базы данных person и сериализации результатов.
- В строке 11 начинается определение read_all (), которое отвечает на конечную точку URL-адреса API REST GET / api / people и возвращает все записи в таблице базы данных пользователей, отсортированные в порядке возрастания по фамилии.
- Строки 19 - 22 сообщают SQLAlchemy запросить таблицу базы данных person для всех записей, отсортировать их в порядке возрастания (порядок сортировки по умолчанию) и вернуть список объектов Person Python в качестве переменных people.
- В строке 24 определение класса Marshmallow PersonSchema становится полезным. Вы создаете экземпляр PersonSchema, передавая ему параметр many = True. Это говорит PersonSchema, что нужно ожидать сериализации, что и является переменной people.
- Строка 25 использует переменную экземпляра PersonSchema (person_schema), вызывая ее метод dump () со списком людей. Результатом является объект, имеющий атрибут данных, объект, содержащий список людей, который можно преобразовать в JSON. Connexion возвращает его в JSON и возвращает как ответ на вызов REST API.
Примечание. Переменная списка людей, созданная в строке 24 выше, не может быть возвращена напрямую, поскольку Connexion не будет знать, как преобразовать поле метки времени в JSON. Возвращение списка людей без его обработки с помощью Marshmallow приводит к длинной трассировке ошибок и, наконец, к этому исключению:
TypeError: Object of type Person is not JSON serializable
Вот еще одна часть модуля person.py, который делает запрос на одного человека из базы данных о людях. Здесь функция read_one (person_id) получает person_id от пути URL REST, указывая, что пользователь ищет конкретного человека. Вот часть обновленного модуля person.py, показывающая обработчик для конечной точки URL-адреса REST GET / api / people / {person_id}:
def read_one(person_id):
"""
This function responds to a request for /api/people/{person_id}
with one matching person from people
:param person_id: ID of person to find
:return: person matching ID
"""
# Get the person requested
person = Person.query \
.filter(Person.person_id == person_id) \
.one_or_none()
# Did we find a person?
if person is not None:
# Serialize the data for the response
person_schema = PersonSchema()
return person_schema.dump(person).data
# Otherwise, nope, didn't find that person
else:
abort(404, 'Person not found for Id: {person_id}'.format(person_id=person_id))
Вот что делает приведенный выше код:
- Строки 10 - 12 используют параметр person_id в запросе SQLAlchemy с использованием метода фильтра объекта запроса для поиска человека с атрибутом person_id, совпадающим с переданным параметром person_id. Вместо использования метода запроса all () используйте метод one_or_none (), чтобы получить одного человека, или верните None, если совпадение не найдено.
- Строка 15 определяет, был ли человек найден или нет.
- Строка 17 показывает, что если человек не был None (соответствующий человек был найден), то сериализация данных немного отличается. Вы не передаете параметр many = True при создании экземпляра PersonSchema (). Вместо этого вы передаете many = False, потому что для сериализации передается только один объект.
- В строке 18 вызывается метод дампа person_schema и возвращается атрибут данных результирующего объекта.
- Строка 23 показывает, что, если person был None (соответствующий человек не был найден), то вызывается метод Flask abort () для возврата ошибки.
Еще одно изменение в person.py - создание нового человека в базе данных. Это дает вам возможность использовать Marshmallow PersonSchema для десериализации структуры JSON, отправленной с HTTP-запросом, для создания объекта Person в SQLAlchemy. Вот часть обновленного модуля person.py, показывающая обработчик для конечной точки REST URL POST / api / people:
def create(person):
"""
This function creates a new person in the people structure
based on the passed-in person data
:param person: person to create in people structure
:return: 201 on success, 406 on person exists
"""
fname = person.get('fname')
lname = person.get('lname')
existing_person = Person.query \
.filter(Person.fname == fname) \
.filter(Person.lname == lname) \
.one_or_none()
# Can we insert this person?
if existing_person is None:
# Create a person instance using the schema and the passed-in person
schema = PersonSchema()
new_person = schema.load(person, session=db.session).data
# Add the person to the database
db.session.add(new_person)
db.session.commit()
# Serialize and return the newly created person in the response
return schema.dump(new_person).data, 201
# Otherwise, nope, person exists already
else:
abort(409, f'Person {fname} {lname} exists already')
Вот что делает приведенный выше код:
- В строках 9 и 10 задаются переменные fname и lname на основе структуры данных Person, отправляемой в качестве тела POST HTTP-запроса.
- Строки 12 - 15 используют класс SQLAlchemy Person для запроса базы данных о существовании человека с теми же именами fname и lname, что и у переданного лица.
- В строке 18 указывается, является ли existing_person None. (Existing_person не был найден.)
- Строка 21 создает экземпляр PersonSchema () с именем schema.
- В строке 22 используется переменная схемы для загрузки данных, содержащихся в переменной параметра person, и создания новой переменной экземпляра SQLAlchemy Person с именем new_person.
- Строка 25 добавляет экземпляр new_person в db.session.
- Строка 26 фиксирует экземпляр new_person в базе данных, которая также присваивает ему новое значение первичного ключа (на основе автоматически увеличивающегося целого числа) и метку времени на основе UTC.
- Строка 33 показывает, что, если existing_person не является None (согласующий человек был найден), то метод Flask abort() вызывается чтобы возвращать ошибку.
Обновление пользовательского интерфейса Swagger
После внесения указанных изменений ваш REST API теперь работает. Внесенные вами изменения также отражаются в обновленном интерфейсе пользовательского интерфейса Swagger и могут взаимодействовать таким же образом. Ниже приведен скриншот обновленного пользовательского интерфейса Swagger, открытого в разделе GET / people / {person_id}. Этот раздел пользовательского интерфейса получает одного человека из базы данных и выглядит так:
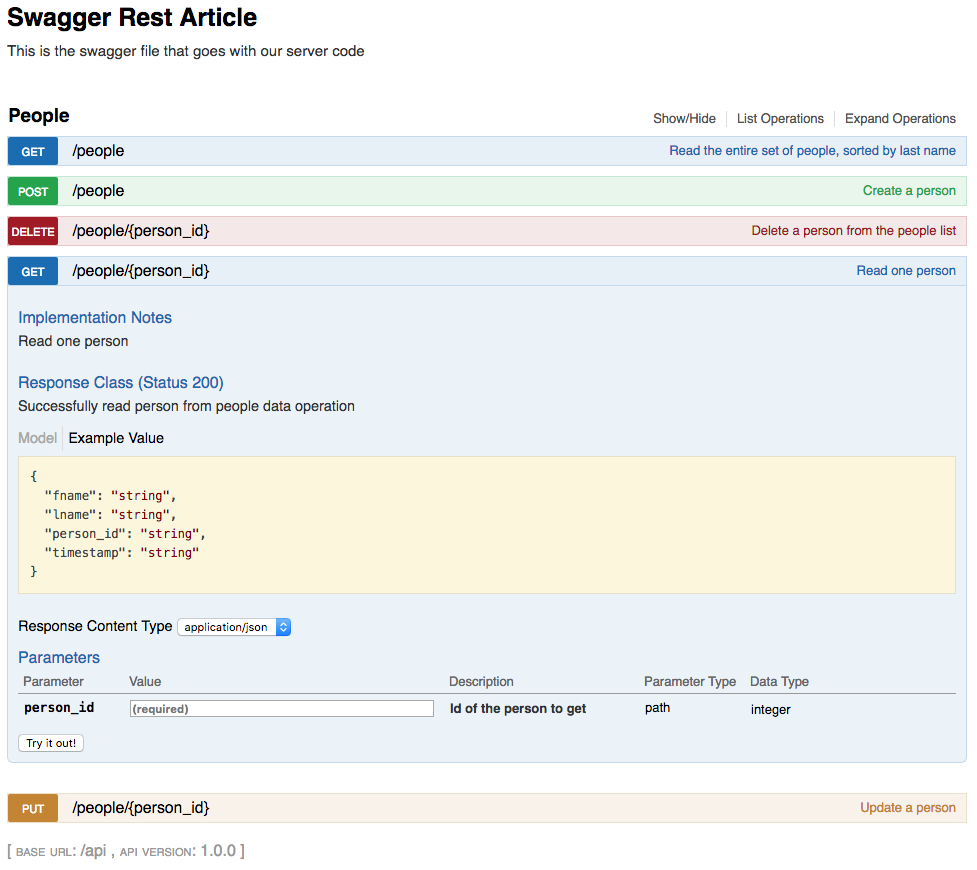
Как показано на снимке экрана выше, параметр пути lname был заменен на person_id, который является первичным ключом для человека в REST API. Изменения в пользовательском интерфейсе являются совокупным результатом изменения файла swagger.yml и изменений кода, внесенных для его поддержки.
Обновление веб-приложения
API REST запущен, а операции CRUD сохраняются в базе данных. Чтобы можно было просматривать демонстрационное веб-приложение, необходимо обновить код JavaScript.
Обновления снова связаны с использованием person_id вместо lname в качестве первичного ключа для персональных данных. Кроме того, person_id присоединяется к строкам таблицы отображения в виде атрибутов данных HTML с именем data-person-id, поэтому значение может быть получено и использовано кодом JavaScript.
Эта статья была посвящена базе данных и тому, как заставить ее использовать ваш REST API, поэтому есть только ссылка на обновленный источник JavaScript, а не обсуждение того, что он делает.
Пример кода
Весь пример кода для этой статьи доступен здесь. Существует одна версия кода, содержащая все файлы, включая служебную программу build_database.py и пример модифицированной программы server.py из части 1.
Вывод
Поздравляем, вы рассмотрели много нового материала в этой статье и добавили полезные инструменты в свой арсенал!
Вы узнали, как сохранять объекты Python в базе данных с помощью SQLAlchemy. Вы также узнали, как использовать Marshmallow для сериализации и десериализации объектов SQLAlchemy и использовать их с JSON REST API. То, что вы узнали, безусловно, было на шаг вперед по сложности от простого REST API части 1, но этот шаг дал вам два очень мощных инструмента, которые можно использовать при создании более сложных приложений.
SQLAlchemy и Marshmallow сами по себе являются удивительными инструментами. Их совместное использование позволяет вам создавать собственные веб-приложения, поддерживаемые базой данных.
В третьей части этой серии вы сосредоточитесь на R-части СУБД: взаимосвязи, которые обеспечивают еще большую мощность при использовании базы данных.