1. Наличие каких компетенций для аналитика вы считаете наиболее важными?
2. Какие языки программирования необходимо изучать будущему аналилитику?
3. Заинтересованы ли вы в студентах-практикантах? Какими компетенециями они должны обладать?
Спиридоновой Надежды
1. Наличие каких компетенций для аналитика вы считаете наиболее важными?
2. Какие языки программирования необходимо изучать будущему аналилитику?
3. Заинтересованы ли вы в студентах-практикантах? Какими компетенециями они должны обладать?
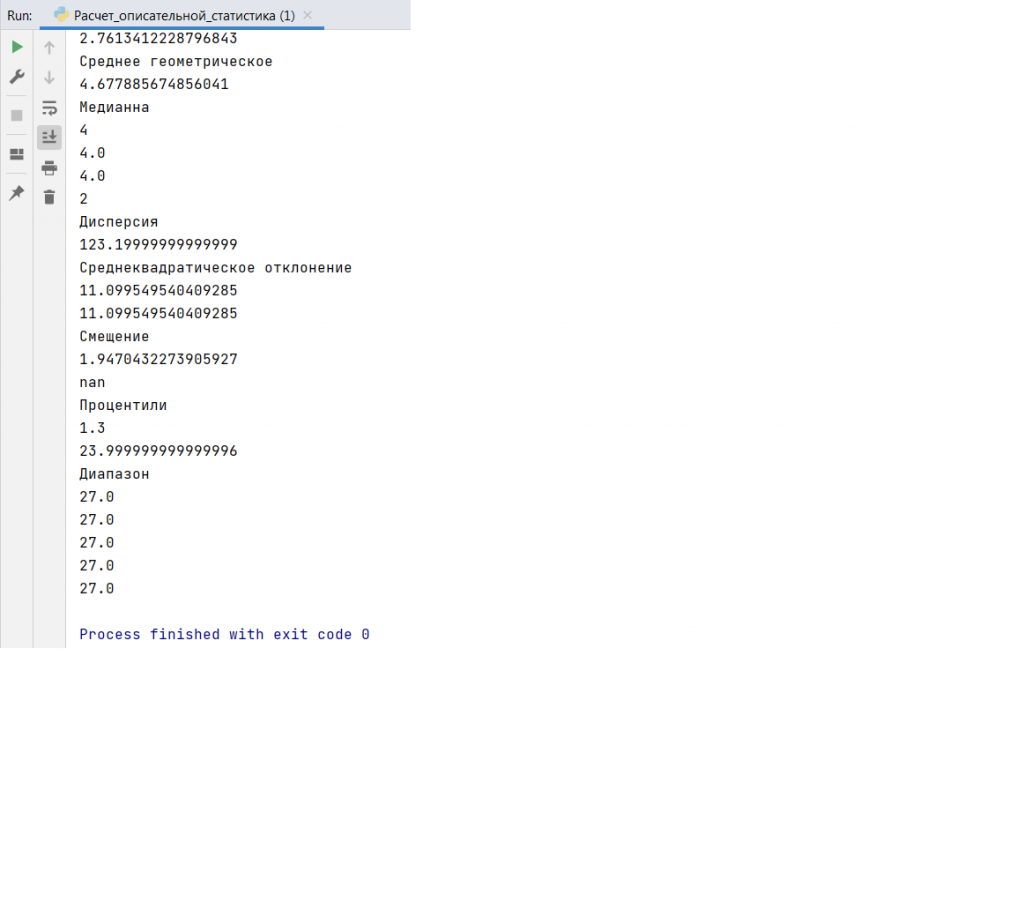
Для изучения статистики загружаем библиотеки: math, numpy, pandas, statistics, scipy.stats. Посмотрим, каким образом можно рассчитать центральные метрики, средневзвешенное, гармоническое среднее, среднее геометрическое, медиану, моду, дисперсию, среднеквадратичное отклонение, смещение, процентили, диапазон. Программный код для расчёта данных показателей приведён ниже.
#
import math
import statistics
import numpy as np
import scipy.stats
import pandas as pd
print("Исходные данные")
x = [8.0, 1, 2.5, 4, 28.0]
x_with_nan = [8.0, 1, 2.5, math.nan, 4, 28.0]
y, y_with_nan = np.array(x), np.array(x_with_nan)
z, z_with_nan = pd.Series(x), pd.Series(x_with_nan)
print(y)
print(y_with_nan)
print(z)
print(z_with_nan)
# Среднее значение
print("Среднее значение")
mean_=sum(x)/len(x)
print(mean_)
mean_=statistics.mean(x)
print(mean_)
m=np.nanmean(y_with_nan)
print(m)
# Средневзвешенное значение
print("Средневзвешенное значение")
x = [8.0, 1, 2.5, 4, 28.0]
w = [0.1, 0.2, 0.3, 0.25, 0.15]
wmean = sum(w[i] * x[i] for i in range(len(x))) / sum(w)
print(wmean)
wmean = sum(x_ * w_ for (x_, w_) in zip(x, w)) / sum(w)
print(wmean)
# Средневзвешенное значение, использование массивов Numpy и Pandas
x = [8.0, 1, 2.5, 4, 28.0]
y, z, w = np.array(x), pd.Series(x), np.array(w)
wmean = np.average(y, weights=w)
print(wmean)
wmean = np.average(z, weights=w)
print(wmean)
# Гармоническое среднее
print("Гармоническое среднее")
hmean = len(x) / sum(1 / item for item in x)
print(hmean)
hmean==scipy.stats.hmean(y)
print(hmean)
# Среднее геометрическое
print("Среднее геометрическое")
gmean = 1
for item in x:
gmean *= item
gmean **= 1 / len(x)
print(gmean)
# Медиана
print("Медиана")
n = len(x)
if n % 2:
median_ = sorted(x)[round(0.5*(n-1))]
else:
x_ord, index = sorted(x), round(0.5 * n)
median_ = 0.5 * (x_ord[index-1] + x_ord[index])
print(median_)
print(z.median())
print(z_with_nan.median())
# Медиана
u = [2, 3, 2, 8, 12]
mode_ = max((u.count(item), item) for item in set(u))[1]
print(mode_)
# Дисперсия
print("Дисперсия")
n = len(x)
mean_ = sum(x) / n
var_ = sum((item - mean_)**2 for item in x) / (n - 1)
print(var_)
# Среднеквадратическое отклонение
print("Среднеквадратическое отклонение")
std_ = var_ ** 0.5
print(std_)
std_=np.std(y, ddof=1)
print(std_)
# Смещение
print("Смещение")
y, y_with_nan = np.array(x), np.array(x_with_nan)
print(scipy.stats.skew(y, bias=False))
print(scipy.stats.skew(y_with_nan, bias=False))
# Процентили
print("Процентили")
y = np.array(x)
print(np.percentile(y, 5))
print(np.percentile(y, 95))
# Диапазон
print("Диапазон")
print(np.amax(y) - np.amin(y))
print(np.nanmax(y_with_nan) - np.nanmin(y_with_nan))
print(y.max() - y.min())
print(z.max() - z.min())
print(z_with_nan.max() - z_with_nan.min())
Результат работы программы представлен ниже.
Для разбиения отдельного pdf документа на страницы воспользуемся следующей программой
#
from PyPDF2 import PdfFileReader, PdfFileWriter
pdf_document = "D:\Надя\Костерин\Поддомены\source\Формула включений и исключений.pdf"
pdf = PdfFileReader(pdf_document)
for page in range(pdf.getNumPages()):
pdf_writer = PdfFileWriter()
current_page = pdf.getPage(page)
pdf_writer.addPage(current_page)
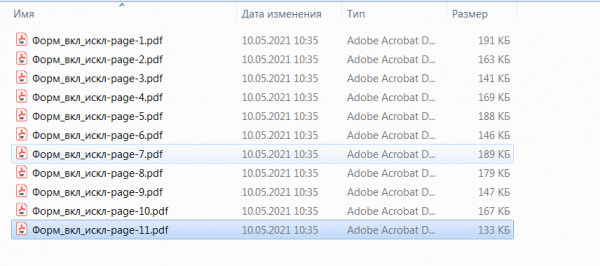
outputFilename = "dist/Форм_вкл_искл-page-{}.pdf".format(page + 1)
with open(outputFilename, "wb") as out:
pdf_writer.write(out)
print("created", outputFilename)
Результат представлен на следующем рисунке
Найти все страницы, где есть заданный текст
#
import fitz
filename = "D:\Надя\Костерин\Поддомены\source\Формула включений и исключений.pdf"
search_term = "множество"
pdf_document = fitz.open(filename)
for current_page in range(len(pdf_document)):
page = pdf_document.loadPage(current_page)
if page.searchFor(search_term):
print("%s найдено на странице %i" % (search_term, current_page+1))
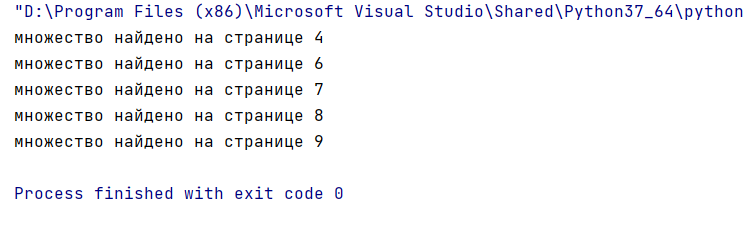
Осуществим поиск в документе Формула включения и исключения.pdf слова «множество».
Результат работы программы представлен ниже.
Добавление водяного знака с помощью PyPDF2
Добавим в pdf файл водяной знак «Черновик». Текст программы
#
# Добавление водяного знака в одностраничный PDF
import PyPDF2
input_file = "D:\Надя\Костерин\Поддомены\source\Задание 12.3.pdf"
output_file = "dist/Водяной_знак-page-drafted.pdf"
watermark_file = "source/Черновик.pdf"
with open(input_file, "rb") as filehandle_input:
# читать содержимое исходного файла
pdf = PyPDF2.PdfFileReader(filehandle_input)
with open(watermark_file, "rb") as filehandle_watermark:
# читать содержание водяного знака
watermark = PyPDF2.PdfFileReader(filehandle_watermark)
# получить первую страницу оригинального PDF
first_page = pdf.getPage(0)
# получить первую страницу водяного знака PDF
first_page_watermark = watermark.getPage(0)
# объединить две страницы
first_page.mergePage(first_page_watermark)
# создать объект записи PDF для выходного файла
pdf_writer = PyPDF2.PdfFileWriter()
# добавить страницу
pdf_writer.addPage(first_page)
with open(output_file, "wb") as filehandle_output:
# записать файл с водяными знаками в новый файл
pdf_writer.write(filehandle_output)
Результат работы программы

Удаление страниц с помощью pdfrw
Для удаления страниц необходимо установить библиотеку pdfrw. Текст программы приведен ниже.
#
# Удалите первые две страницы (титульный лист) из PDF
from pdfrw import PdfReader, PdfWriter
input_file = "D:\Надя\Костерин\Поддомены\source\Формула включений и исключений.pdf"
output_file = "dist/Удаление_страниц-page-drafted.pdf"
# Определить объекты чтения и записи
reader_input = PdfReader(input_file)
writer_output = PdfWriter()
# Перейти на страницу один за другим
for current_page in range(len(reader_input.pages)):
if current_page > 1:
writer_output.addpage(reader_input.pages[current_page])
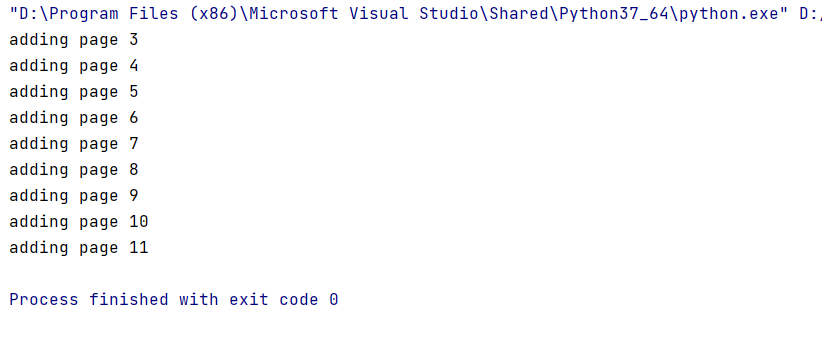
print("adding page %i" % (current_page + 1))
# Записать измененный контент на диск
writer_output.write(output_file)
Результат работы программы – сформирован новый файл, у которого вырезано 2 первые страницы.
Если необходимо обнаружить поддомены конкретного Web - сайта, то можно воспользоваться следующей программой. Используется метод полного перебора, будут проверяться все общие имена поддоменов этого конкретного домена, если будет получен ответ от сервера, то это означает, что поддомен существует. Был составлен список поддоменов для сканирования и помещен в файл «subdomains.txt».
#
import requests
# домен для поиска поддоменов
domain = "susu.ru"
# читать все поддомены
file = open("D:\Надя\Костерин\Поддомены\subdomains.txt")
# прочитать весь контент
content = file.read()
# разделить на новые строки
subdomains = content.splitlines()
# список обнаруженных поддоменов
discovered_subdomains = []
for subdomain in subdomains:
# создать URL
url = f"http://{subdomain}.{domain}"
try:
# если возникает ОШИБКА, значит, субдомен не существует
requests.get(url)
except requests.ConnectionError:
# если поддомена не существует, просто передать, ничего не выводить
pass
else:
print("[+] Обнаружен поддомен:", url)
# добавляем обнаруженный поддомен в наш список
discovered_subdomains.append(url)
# сохраняем обнаруженные поддомены в файл
with open("discovered_subdomains.txt", "w") as f:
for subdomain in discovered_subdomains:
print(subdomain, file=f)
В результате работы программы были получены следующие результаты для домена susu.ru :
"D:\Program Files (x86)\Microsoft Visual Studio\Shared\Python37_64\python.exe" D:/Надя/Костерин/Поддомены/Сканерподдоменов.py
[+] Обнаружен поддомен: http://mail.susu.ru
[+] Обнаружен поддомен: http://test.susu.ru
[+] Обнаружен поддомен: http://lists.susu.ru
[+] Обнаружен поддомен: http://support.susu.ru
[+] Обнаружен поддомен: http://wiki.susu.ru
[+] Обнаружен поддомен: http://media.susu.ru
[+] Обнаружен поддомен: http://my.susu.ru
[+] Обнаружен поддомен: http://sites.susu.ru
[+] Обнаружен поддомен: http://info.susu.ru
[+] Обнаружен поддомен: http://office.susu.ru
Process finished with exit code 0