Создала объекты на карте с 250 по 345 и заполнила данными их атрибуты.
Автор: Спиридонова Надежда
Производственная практика 2.07.2021
Создала объекты на карте с 190 по 250 и заполнила данными их атрибуты.
Производственная практика (01.07.2021)

В свой четвертый день практики я заполняла данными атрибуты с номера 120 по 190. Изменила прорисовку улиц и некоторых домов, которые были не точно отмечены на карте. В целом, работа была интерсной, буду продолжать в том же духе.
Производственная практика 30.06.2021
Создала объекты на карте с 50 по 120 и заполнила данными их атрибуты .
Производственная практика 29.06.2021
Свой второй день практики я начала с установки программы QGIS. Изучила методическое руководство по использованию программного обеспечения QGIS. Далее в программе я попыталась создавать и редактировать объекты на карте и данные атрибутов. Создала и заполнила данными объекты с 1 по 50.
Производственная практика 28.06.2021
Содержание работы в первый день производственной практики в Областном государственном бюджетном учреждение «Челябинский региональный центр навигационно-информационных технологий»:
1) Знакомство с предприятием.
2) Вводный инструктаж. Ознакомление с техникой безопасности на предприятии.
3) Структура предприятия. Основные направления деятельности. Функции подразделения организации, ее роль и взаимодействие с другими отделами. Основные квалификационные требования, предъявляемые к должности сотрудников. Описание обязанностей в работе подразделения, характеристика своей должности.
Рецензия
Рецензия на перевод статьи студентки группы ЭУ-220 Поповой Эвелины Антоновны «Блокнот Jupyter: введение»
В статье описывается веб-приложение Jupyter Notebook, которое используется для создания и обмена документами, содержащими код, изображения, комментарии, формулы и графику. Подробно рассмотрена установка, запуск, создание документов. Описан экспорт полученного документа в разные форматы. Добавление новых функций с помощью расширений.
Из достоинств следует отметить: наличие иллюстраций, позволяющих понять интерфейс веб-приложения.
В качестве недостатков следует выделить: некоторые английские термины не заменены на русские аналоги.
В целом, Попова Эвелина Антоновна справилась с поставленной задачей и заслуживает оценку "отлично".
Bokeh - библиотека для интерактивной визуализации данных
Bokeh - библиотека для интерактивной визуализации данных. Он отображает графику с помощью HTML и JavaScript. Что делает его удобным для создания веб-панелей и приложений.
#
# Библиотеки Bokeh
from bokeh.io import output_file
from bokeh.plotting import figure, show
# Рисунок будет отображен в статическом HTML-файле с именем output_file_test.html
output_file('output_file_test.html',
title='Empty Bokeh Figure')
# Настроить общий объект figure()
fig = figure()
# Посмотрите, как это выглядит
show(fig)
Результат работы программы:

Рисование данных с помощью глифов
#
# Библиотеки Bokeh
from bokeh.io import output_file
from bokeh.plotting import figure, show
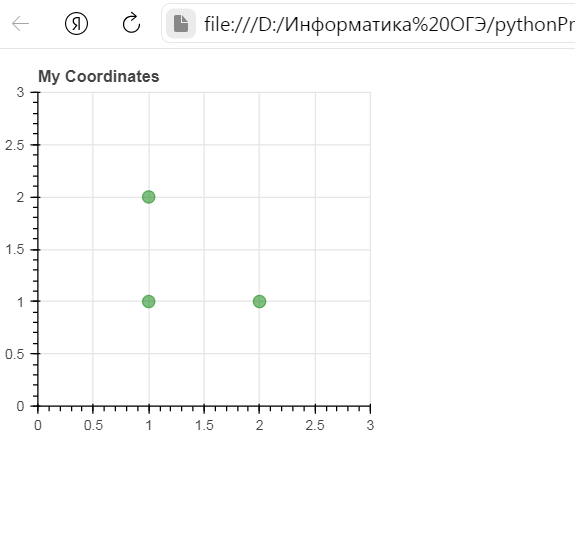
# Мои данные о координатах x-y
x = [1, 2, 1]
y = [1, 1, 2]
# Рисунок будет отображен в статическом HTML-файле с именем output_file_test.html
output_file('output_file_test.html',
title='Empty Bokeh Figure')
# Настроить общий объект figure()
fig = figure(title='My Coordinates',
plot_height=300, plot_width=300,
x_range=(0, 3), y_range=(0, 3),
toolbar_location=None)
# Нарисуйте координаты в виде кругов
fig.circle(x=x, y=y,
color='green', size=10, alpha=0.5)
# Показать сюжет
show(fig)
Результат работы программы:
Программный код.
#
# Библиотеки Bokeh
from bokeh.io import output_file
from bokeh.plotting import figure, show
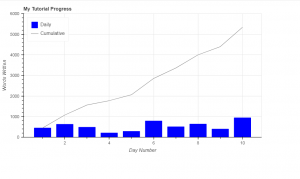
# Мои данные о подсчете слов
day_num = np.linspace(1, 10, 10)
daily_words = [450, 628, 488, 210, 287, 791, 508, 639, 397, 943]
cumulative_words = np.cumsum(daily_words)
# Рисунок будет отображен в статическом HTML-файле с именем output_file_test.html
output_file('output_file_test.html',
title='Empty Bokeh Figure')
# Создаем фигуру с осью x типа datetime
fig = figure(title='My Tutorial Progress',
plot_height=400, plot_width=700,
x_axis_label='Day Number', y_axis_label='Words Written',
x_minor_ticks=2, y_range=(0, 6000),
toolbar_location=None)
# Ежедневные слова будут представлены в виде вертикальных полос (столбцов)
fig.vbar(x=day_num, bottom=0, top=daily_words,
color='blue', width=0.75,
legend='Daily')
# Накопленная сумма будет линией тренда
fig.line(x=day_num, y=cumulative_words,
color='gray', line_width=1,
legend='Cumulative')
# Поместите легенду в левый верхний угол
fig.legend.location = 'top_left'
# Давайте проверим
show(fig)
Результат работы программы:
Визуализация данных
Питон даёт возможность представить имеющиеся числовые данные в виде гистограмм, круговых диаграмм, графиков. Для этого необходимо загрузить библиотеку: matplotlib.pyplot. Ниже представлены коды программ и результат их выполнения.
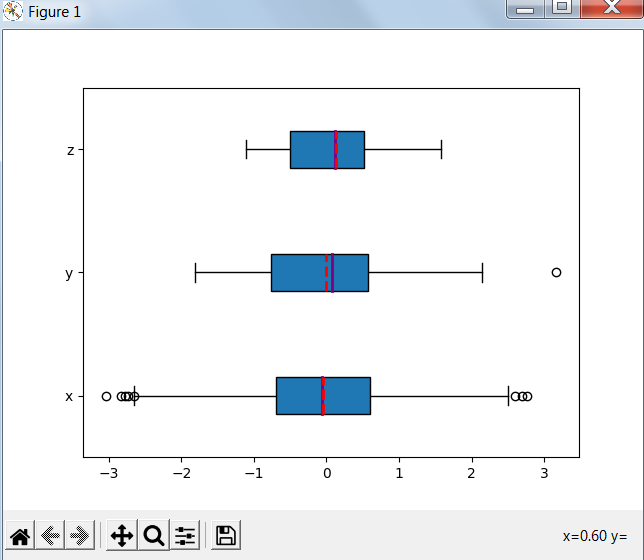
Box Plots
#
import matplotlib.pyplot as plt
import math
import statistics
import numpy as np
import scipy.stats
import pandas as pd
np.random.seed(seed=0)
x = np.random.randn(1000)
y = np.random.randn(100)
z = np.random.randn(10)
fig, ax = plt.subplots()
ax.boxplot((x, y, z), vert=False, showmeans=True, meanline=True,
labels=('x', 'y', 'z'), patch_artist=True,
medianprops={'linewidth': 2, 'color': 'purple'},
meanprops={'linewidth': 2, 'color': 'red'})
plt.show()
Результат работы программы:
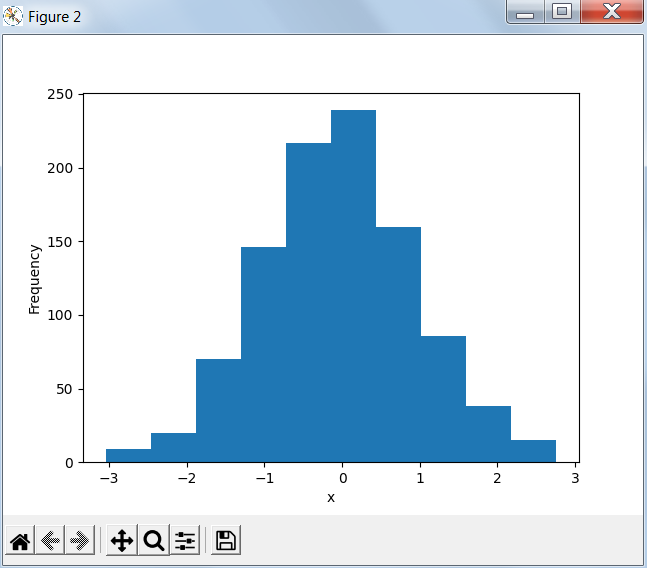
Гистограмма
#
# Гистограммы
hist, bin_edges = np.histogram(x, bins=10)
print(hist)
print(bin_edges)
fig, ax = plt.subplots()
ax.hist(x, bin_edges, cumulative=False)
ax.set_xlabel('x')
ax.set_ylabel('Frequency')
plt.show()
Результат работы программы:
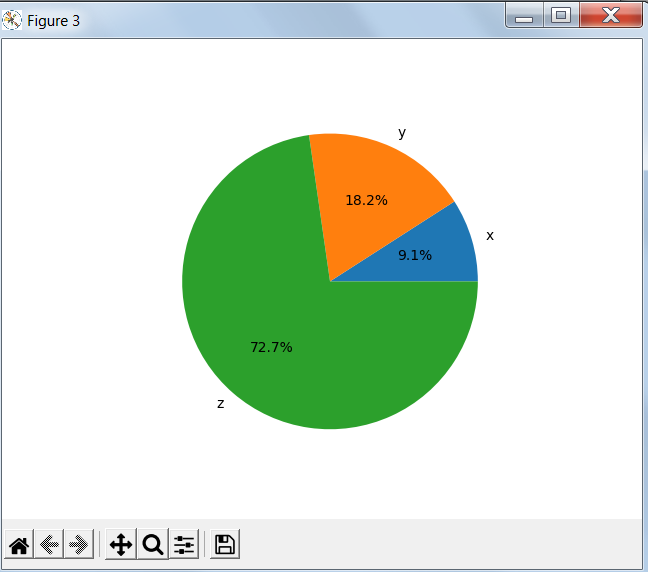
Pie Charts круговые диаграммы
#
x, y, z = 128, 256, 1024
fig, ax = plt.subplots()
ax.pie((x, y, z), labels=('x', 'y', 'z'), autopct='%1.1f%%')
plt.show()
Результат работы программы:
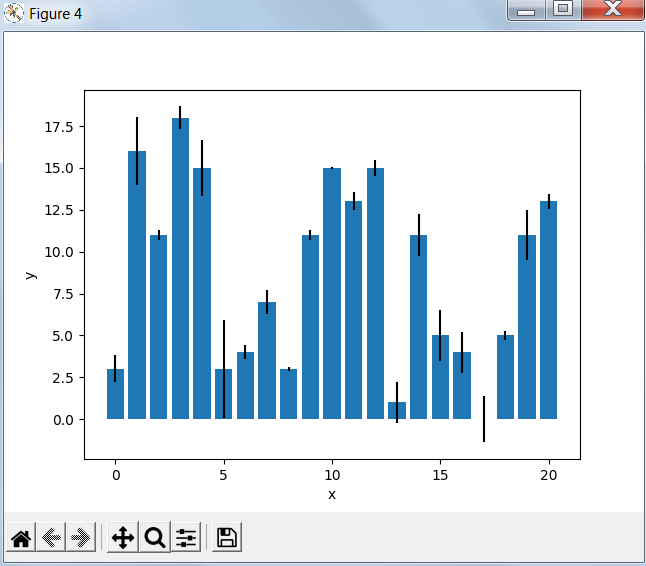
Bar Charts
#
x = np.arange(21)
y = np.random.randint(21, size=21)
err = np.random.randn(21)
fig, ax = plt.subplots()
ax.bar(x, y, yerr=err)
ax.set_xlabel('x')
ax.set_ylabel('y')
plt.show()
Результат работы программы:
Описательная статистика на Python
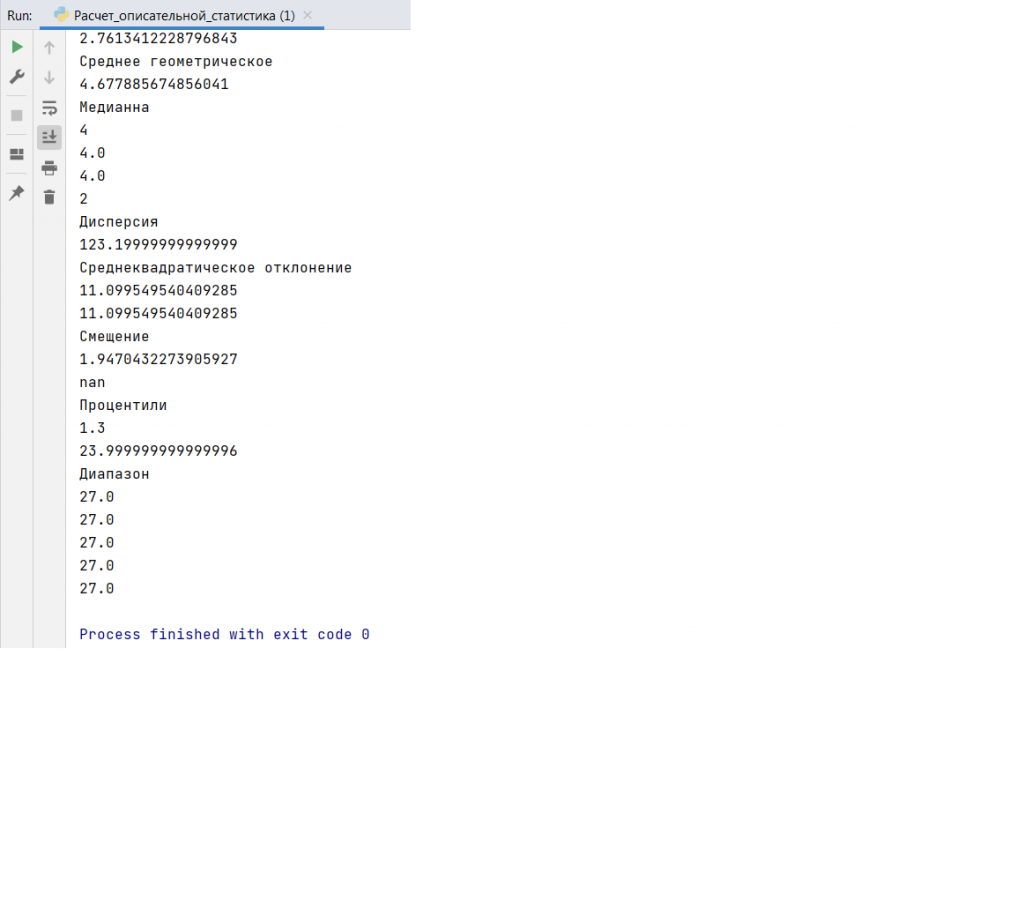
Для изучения статистики загружаем библиотеки: math, numpy, pandas, statistics, scipy.stats. Посмотрим, каким образом можно рассчитать центральные метрики, средневзвешенное, гармоническое среднее, среднее геометрическое, медиану, моду, дисперсию, среднеквадратичное отклонение, смещение, процентили, диапазон. Программный код для расчёта данных показателей приведён ниже.
#
import math
import statistics
import numpy as np
import scipy.stats
import pandas as pd
print("Исходные данные")
x = [8.0, 1, 2.5, 4, 28.0]
x_with_nan = [8.0, 1, 2.5, math.nan, 4, 28.0]
y, y_with_nan = np.array(x), np.array(x_with_nan)
z, z_with_nan = pd.Series(x), pd.Series(x_with_nan)
print(y)
print(y_with_nan)
print(z)
print(z_with_nan)
# Среднее значение
print("Среднее значение")
mean_=sum(x)/len(x)
print(mean_)
mean_=statistics.mean(x)
print(mean_)
m=np.nanmean(y_with_nan)
print(m)
# Средневзвешенное значение
print("Средневзвешенное значение")
x = [8.0, 1, 2.5, 4, 28.0]
w = [0.1, 0.2, 0.3, 0.25, 0.15]
wmean = sum(w[i] * x[i] for i in range(len(x))) / sum(w)
print(wmean)
wmean = sum(x_ * w_ for (x_, w_) in zip(x, w)) / sum(w)
print(wmean)
# Средневзвешенное значение, использование массивов Numpy и Pandas
x = [8.0, 1, 2.5, 4, 28.0]
y, z, w = np.array(x), pd.Series(x), np.array(w)
wmean = np.average(y, weights=w)
print(wmean)
wmean = np.average(z, weights=w)
print(wmean)
# Гармоническое среднее
print("Гармоническое среднее")
hmean = len(x) / sum(1 / item for item in x)
print(hmean)
hmean==scipy.stats.hmean(y)
print(hmean)
# Среднее геометрическое
print("Среднее геометрическое")
gmean = 1
for item in x:
gmean *= item
gmean **= 1 / len(x)
print(gmean)
# Медиана
print("Медиана")
n = len(x)
if n % 2:
median_ = sorted(x)[round(0.5*(n-1))]
else:
x_ord, index = sorted(x), round(0.5 * n)
median_ = 0.5 * (x_ord[index-1] + x_ord[index])
print(median_)
print(z.median())
print(z_with_nan.median())
# Медиана
u = [2, 3, 2, 8, 12]
mode_ = max((u.count(item), item) for item in set(u))[1]
print(mode_)
# Дисперсия
print("Дисперсия")
n = len(x)
mean_ = sum(x) / n
var_ = sum((item - mean_)**2 for item in x) / (n - 1)
print(var_)
# Среднеквадратическое отклонение
print("Среднеквадратическое отклонение")
std_ = var_ ** 0.5
print(std_)
std_=np.std(y, ddof=1)
print(std_)
# Смещение
print("Смещение")
y, y_with_nan = np.array(x), np.array(x_with_nan)
print(scipy.stats.skew(y, bias=False))
print(scipy.stats.skew(y_with_nan, bias=False))
# Процентили
print("Процентили")
y = np.array(x)
print(np.percentile(y, 5))
print(np.percentile(y, 95))
# Диапазон
print("Диапазон")
print(np.amax(y) - np.amin(y))
print(np.nanmax(y_with_nan) - np.nanmin(y_with_nan))
print(y.max() - y.min())
print(z.max() - z.min())
print(z_with_nan.max() - z_with_nan.min())
Результат работы программы представлен ниже.