

Некоторые консультанты убеждены в том, что для того, чтобы провести какие-то маркетинговые исследования, нужно вынимать стороннюю компанию и тратить достаточно значительные бюджеты. Но тут нельзя так однозначно ответить. С одной стороны - маркетолог внутри компании может и способен провести часть этих исследований, а с другой стороны - если в компании этого не делается, то это означает лишь то, что маркетолог либо не хочет, либо не умеет пользоваться общепризнанными технологиями. И для анализа внешней среды главное понять следующие моменты:
1) Уровень конкурентного окружения. И для того, чтобы его понять, существует два метода. Первый - это интернет-поиск, который предполагает просмотр интернет-ресурсов конкурентов, а именно: как они себя позиционируют, какие продукты предлагают, каковы ценовые предложения на сайте компании и так далее. Помимо этого, необходимо просмотреть ключевые поисковые запросы в «Яндексе» и «Google», по которым вы предполагаете, что ваши клиенты вас ищут, а также просмотр по рекламным позициям кто из конкурентов какую рекламу даёт. У кого-то это будут лэндинговые страницы, посадочные страницы с уникальными конкурентными предложениями, у кого-то будет просто имиджевая реклама. Второй метод – это прозвон ваших конкурентов, их отдела продаж, где задаёте те вопросы, на которые вы хотите получить ответы. В данном случае исследование получается более качественное, когда интервьюер прикидывается полным профнепригодным человеком в данной отрасли и задаёт те вопросы которые мог бы сформулировать именно реальный клиент.
2) Портрет целевой аудитории компании. Внутри целевой аудитории находятся несколько разных сегментов, которые, бывает, не учитываются совсем. И сегментирование рынка производится исключительно по психо-демографическим параметрам: возраст, пол, место проживания, уровень дохода и так далее. Но на сегодняшний момент эти факторы являются вторичными, ведь сегмент – это часть потребительского рынка, которая к вашему продукту предъявляет идентичные требования, являющимися ценностями целевой аудитории. Из всего этого возникает вопрос, как же просегментировать аудиторию? На первом этапе, необходимо проработать гипотезы, которые мы предполагаем, что являются ценностями со стороны наших сегментов. Этих потребительских ценностей может быть достаточно большое количество. И, к сожалению, если компания этим не занимается и не уделяет достаточно внимания разработке продукта именно на языке ценностей потребительской аудитории, то она скатывается в единственную потребительскую ценность – это цена. И там начинает толкаться со всеми другими конкурентами, которые предлагают аналогичный, ничем не отличающийся товар. И здесь выигрывает тот, кто даст более низкую цену. Многие ошибочно считают, что сегодня рынку ничего кроме цены неинтересно. Это утверждение означает только то, что вы не просегментировали, не посмотрели на все потребительские ценности, которые есть на рынке. Так какие они могут быть? Например, ценность экономии времени, под которую затачиваются все интернет-магазины, предоставляя возможность не ходить по магазинам, а сделать заказ через интернет.
3) Продукт. Данный вопрос, к сожалению, проработан на сегодняшний момент у достаточно небольшого числа компаний. Разработка продукта – это реализация ценностей, которые вы выявили со стороны своей аудитории, в ваш продукт. Это будет либо модификация продукта, либо его усовершенствование, либо это будут какие-то дополнительные сервисные предложения.
4) Управления активной клиентской базой. Значительная доля компании работают со своей клиентской базой практически вслепую: они не понимают, кто потенциальная аудитория, потому что не проанализировали потребительские ценности; не совсем понимают с работают, от чего теряют клиентов; почему клиенты реже покупают или недостаточно высокий чек и так далее. Так вот для анализа активной клиентской базы есть достаточно распространенный метод ABC-анализа, суть которого достаточно хорошо описана в интернете.
5) Возможно также применить и очень эффективную методику, а именно: SWOT-анализ. SWOT-анализ – это анализ сильных и слабых сторон внутри компании и анализ возможностей и угроз со стороны. Чтобы он имел практическое применение, необходимо всегда анализировать проблемные поля бизнеса. И здесь вы получите огромное количество инсайтов и готовых решений, что вам необходимо сделать в случае наступления внешнего фактора, то есть возможности или угрозы.
Визуализация пандемии коронавируса с помощью фоновых картограмм
Визуализация данных это наиболее эффективный метод иллюстрации и объяснения сложной информации, особенно числовых данных, в простой и удобоваримой форме. Кроме того, при грамотном исполнении, инфографика при интерпретации данных позволяет уменьшить или смягчить систематические ошибки. Один из заслуживающих особого внимания видов визуализации — анимированные фоновые картограммы или хороплеты. И в данной статье мы, используя эти виды, визуализируем пандемию коронавируса, что на данный момент очень актуально.
Но прежде чем начать, давайте разберем определения. Фоновая картограмма или хороплет — это тип тематической карты, на которой области или регионы заштрихованы пропорционально и в соответствии со значением заданного измерения данных.
Статические хороплеты наиболее полезны, когда надо сравнить какие то показатели по регионам. Например, сравнить уровень преступности в данный момент в каждом субъекте Российской Федерации, что можно визуализировать с помощью статической фоновой картограммы.
Анимированная или динамическая фоновая картограмма похожа на статическую, за исключением того, что добавляется время. Это третье измерение делает визуализацию исключительно интересной и мощной.
Для визуализации пандемии коронавируса, я использовал набор данных Novel Corona Virus 2019 от Kaggle, который можно найти здесь. Набор данных получен из нескольких источников, включая Всемирную организацию здравоохранения, Национальную комиссию здравоохранения Китайской Народной Республики и Центры США по контролю за заболеваниями.
Статический хороплет
Начнем мы с создания статического хороплета. Работать я буду в привычном мне PyCharm. Первым делом, я открываю редактор и создаю проект. После создания, я добавляю в него папку, под названием “data”, где у меня будет хранится файл csv формата, скаченный с Kaggle и содержащий данные о пандемии по всему миру.
После этого, я, через терминал, устанавливаю необходимые библиотеки. Команды для установки представлены ниже:
pip install numpy pip install pandas pip install plotly
Проделав операции выше, создаем python файл, и мы готовы к визуализации. Код для этой инфографики выглядит следующим образом:
#Статический хороплет
# Импорт библиотек
import numpy as np
import pandas as pd
import plotly as py
import plotly.express as px
import plotly.graph_objs as go
from plotly.subplots import make_subplots
from plotly.offline import download_plotlyjs, init_notebook_mode, plot, iplot
# Чтение данных
df = pd.read_csv("data/covid_19_data.csv")
# Переименуем колонки
df = df.rename(columns={'Country/Region':'Страна'})
df = df.rename(columns={'ObservationDate':'Дата'})
df = df.rename(columns={'Confirmed':'Подтверждено'})
# Манипуляции с оригиналом Dataframe
df_countries = df.groupby(['Страна', 'Дата']).sum().reset_index().sort_values('Дата', ascending=False)
df_countries = df_countries.drop_duplicates(subset = ['Страна'])
df_countries = df_countries[df_countries['Подтверждено']>0]
# Создание фоновой картограммы
fig = go.Figure(data=go.Choropleth(
locations = df_countries['Страна'],
locationmode = 'country names',
z = df_countries['Подтверждено'],
colorscale = 'Reds',
marker_line_color = 'black',
marker_line_width = 0.5,
))
fig.update_layout(
title_text = 'Подтверждённые заболевания 28 марта 2020',
title_x = 0.5,
geo=dict(
showframe = False,
showcoastlines = False,
projection_type = 'equirectangular'
)
)
fig.write_html('Static_choroplete.html', auto_open=True)
Здесь, мы импортируем установленные ранее библиотеки, после читаем csv файл из которого будем брать данные, указывая при этом его местонахождение и название. Далее, переименовываем колонки для удобного восприятия и проводим некоторые манипуляции с оригиналом Dataframe: группировки и возвращения ряда с удаленными повторяющимися значениями. После создаем фоновую картограмму и последней командой мы указываем на создание и запуск html файла, содержащий наши данные. Результат представлен ниже:
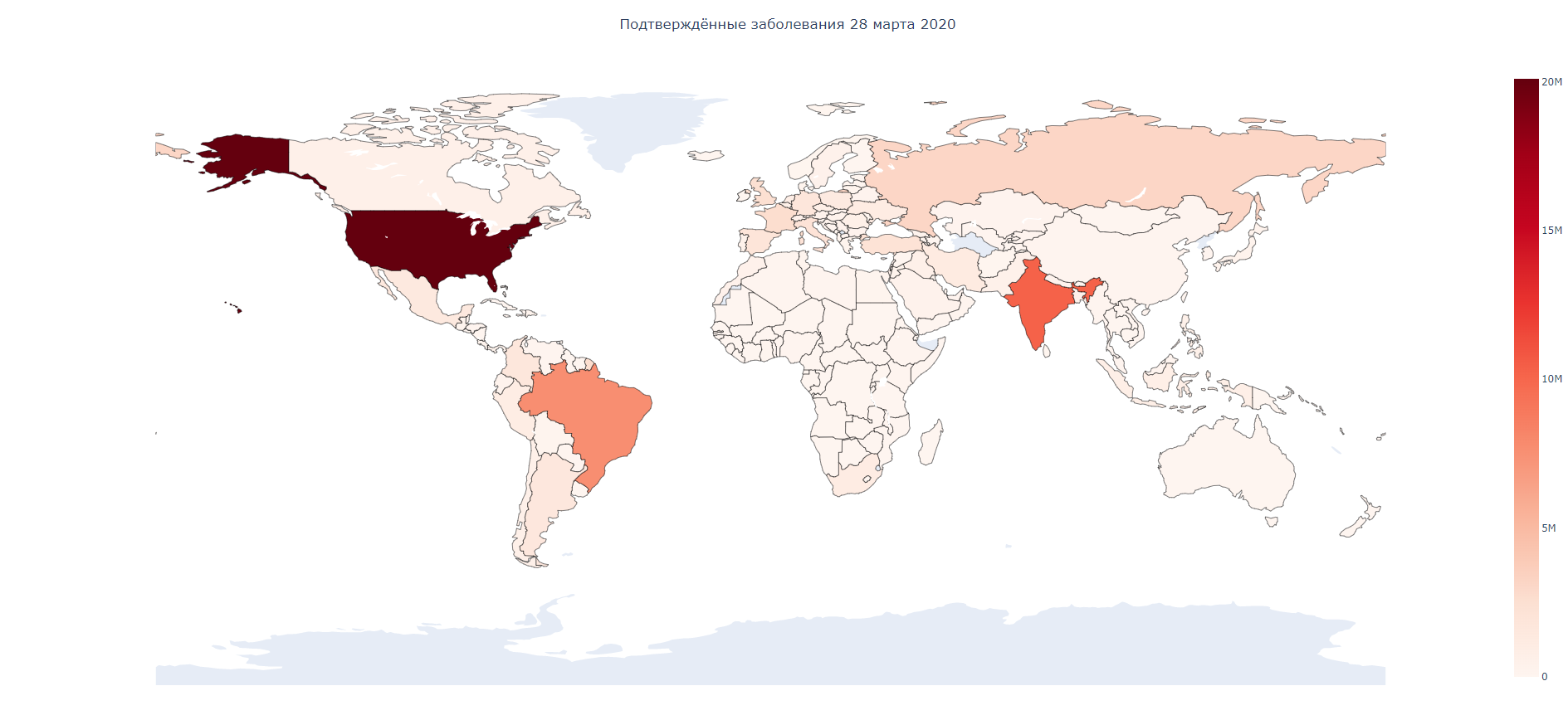
На рисунке, представлена статическая диаграмма общего количества подтвержденных случаев коронавируса по странам по состоянию на 28 марта 2020 года. Вы можете видеть, что страны с наибольшим количеством подтверждённых случаев заболевания — это США, Китай и Италия, а также несколько других европейских стран.
Анимированная фоновая картограмма
Сейчас, вы увидите, насколько, по сравнению со статической, более эффектна и интересна анимированная фоновая картограмма. Для этого, создаем новый python файл и прописываем следующий код:
#Анимированная фоновая картограмма
# Импорт библиотек
import numpy as np
import pandas as pd
import plotly as py
import plotly.express as px
import plotly.graph_objs as go
from plotly.subplots import make_subplots
from plotly.offline import download_plotlyjs, init_notebook_mode, plot, iplot
# Чтение данных
df = pd.read_csv("data/covid_19_data.csv")
# Переименуем колонки
df = df.rename(columns={'Country/Region': 'Страна'})
df = df.rename(columns={'ObservationDate': 'Дата'})
df = df.rename(columns={'Confirmed': 'Подтверждено'})
# Манипуляции с оригиналом Dataframe
df_countrydate = df[df['Подтверждено'] > 0]
df_countrydate = df_countrydate.groupby(['Дата', 'Страна']).sum().reset_index()
df_countrydate
# Создание фоновой картограммы
fig = px.choropleth(df_countrydate,
locations="Страна",
locationmode="country names",
color="Подтверждено",
hover_name="Страна",
animation_frame="Дата"
)
fig.update_layout(
title_text='Глобальное распространение короновируса',
title_x=0.5,
geo=dict(
showframe=False,
showcoastlines=False,
))
fig.write_html('Animated_background_cartogram.html', auto_open=True)
В данном коде, мы проделываем те же операции, что и при статическом хороплете, но с небольшими отличиями. Результат представлен ниже:
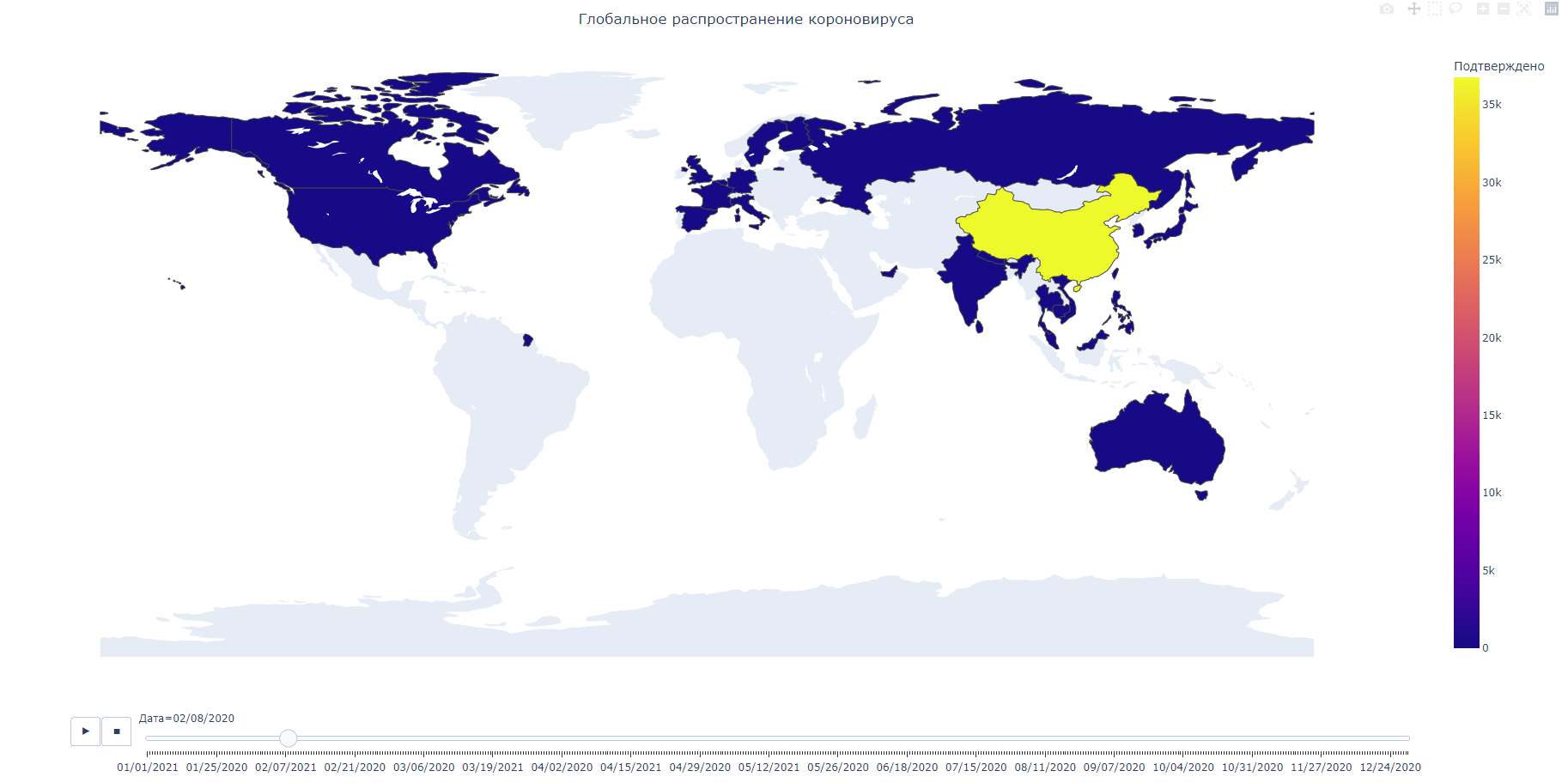
На рисунке, мы видим общее количество подтвержденных случаев коронавируса по странам во времени. И вы можете видеть, что до недавнего времени больше всего заболевших было в Китае.
Конспект лекции "Андрей Себрант - место человека в мире технологий"
Должен ли инженер думать о возможном вреде технологии при её создании?
Нужно быть одержимым идеей, чтобы добиться успеха в том, что ты делаешь. Задумываться над этикой не нужно, отвлекаться на это – помеха конечному результату.
Должны ли этик и инженер работать в паре?
Этику и инженеру не нужно работать в паре. Это не позволит достичь конечного результата, этик будет «мешать» этому.
О машинном обучении.
До появления машинного обучения единственным способом обучить машину – описать пошагово, что необходимо делать. Сейчас, это происходит за счет обучения машины действиями, которые мы сами до конца не понимаем, мы делаем это на подсознании.
В чем машины заменят людей?
Например, сейчас уже существуют машины, которые заменяют дворника и убирают мусор. Но гораздо сложнее заменить сантехника, ведь объяснить машине, как в миллионах домов состоит коммуникация труб, узлов, объяснить, как это чинить и ползать там, то проще иметь человека. Это уже более сложная и дорогостоящая задача, чем заменить дворника.
Можем ли мы прогнозировать будущее с помощью больших данных?
Нет, люди не могут прогнозировать будущее с помощью больших данных, потому что никакие большие данные не позволяют предсказать прорыв человечества в той или иной сфере. И через 20 лет могут возникнуть такие технологии, про которые никто из нас сейчас не догадывается, поэтому спрогнозировать будущее не получится.
Какое будущее ждет Россию?
Исходя из истории, тренд, где жертвой становится какой-либо класс, повторится еще раз. Сейчас, офисные работы среднего класса населения очень легко автоматизировать и удар будет происходить именно по ним. Поэтому и приводился пример с сантехником, ведь, казалось бы, его заменить очень сложно, а бухгалтера легко. Вот этот тренд очень сильно, скорее всего, и затронет нашу страну.
Про аналитику персональных данных.
Анализировать персональные данные человека не желательно. Когда ты начинаешь ему “подсовывать” что-то, что ему не интересно или же точку зрения, с которой он не согласен, то ему это не нравится, и он уходит на другой сервис.
Есть ли персональные данные, которые нельзя анализировать?
Большинство компаний, которые живут по рекламной модели, стараются не анализировать данные о состоянии здоровья человека. Ведь человек, когда смотрит симптомы болезни или читает информацию о ней, при этом не желая рассказывать об этом своим родственникам, не хочет, чтобы ему в дальнейшем предлагали к просмотру информацию об этом. Например, когда он со своими родственниками или знакомыми захочет что-нибудь посмотреть в интернете и будет идти сплошная реклама средств лечения от этой болезни, то будут возникать вопросы, которые пользователь хочет избежать. Как итог, фармакологическая компания ничего не заработала, а пользователь ушел на сторонний сервис.
Есть ли персональные данные, которые Яндекс осознанно не собирает?
Есть. К ним относится история по здоровью, личная переписка и так далее. Почему нельзя анализировать личную переписку? Все очень просто. Например, если у человека ушел из жизни близкий человек, и он делится этим в переписке, то алгоритм будет предлагать ему ритуальные услуги. Это очень сильно обидит человека, плюс породит огромный скандал, который повлияет на репутацию компании. Именно поэтому, никто не анализирует личную переписку.
Как Яндекс обрабатывает персональные данные?
Обработка персональных данных в Яндексе производится используя этические нормы.
Конспект лекции "Укрепление доверия россиян к искусственному интеллекту и развитие отечественной отрасли ИИ"
Искусственный интеллект – система или набор алгоритмов, воспроизводящий определённые когнитивные способности людей, благодаря которым человек ставит своей целью принятие решений или помощь в принятии решений. И с этой точки зрения можно сказать, что технологии искусственного интеллекта в наше время абсолютно везде. Например, во всех гаджетах, интерфейсах и поверхностях, с которыми люди взаимодействуют. Ведь любой наш гаджет, приложение, которое мы открываем, практически всё, что мы говорим или слышим, обрабатывается через системы распознавания речи, системы компьютерного зрения. Это используются для того, чтобы человек, например, который включает приложение, действительно был владелец телефона и так далее.
Основная задача заключается в том, чтобы объёмами цифр занималась машина, а не огромное количество людей в штате, ведь человек может совершать ошибки.
Кроме того, там, где не опасно, человек делегирует решения машине, а там, где существует вопрос какой-то этической дилеммы – человек есть и будет финальной точкой принятия решения. В этом смысле технологии искусственного интеллекта помогают людям. Например, современная авиатехника имеет широкие возможности автопилотирования, но в какие-то момент подключается живой пилот. Поэтому, благодаря искусственному интеллекту мы освобождаем человека для того, чтобы делать более сознательные или творческие задачи, что порождает в том числе новые направления и навыки.
Но что делать если человек теряет свои когнитивные функции? Ведь если он их не тренирует, понятно, что они снижаются. (для чего детям уметь считать в столбик, если они могут открыть калькулятор на телефоне, компьютере и посчитать там) Над этим вопросом сейчас думают многие – и разработчики, и те, кто использует технологические системы искусственного интеллекта, которые есть. Но тут стоит вопрос выбора людей - отказываясь от участия в каких-то мыслительных или рутинных действиях, мы проходим через так называемый «рескиллинг». Но проходя рескиллинг, мы начинаем осваивать новое.
Более ли консервативен и осторожен искусственный интеллект чем человек? Все это зависит от того, как его обучают. Если мы задаём ему цель быть максимально консервативным и минимизировать негативные последствия – значит, он будет работать консервативно. В конечном счёте, за любым алгоритмом стоит разработчик. Это очень важный момент, за которым важно закрепить ответственность – так у людей будет понимание, что где-то должен быть стоп-кран, или возможность корректировки решения, предлагаемого искусственным интеллектом, если что-то идёт не так.
По сценарию вышедшего из-под контроля искусственного интеллекта, который не только сам принимает решения, а уже видя, что человек для него представляет опасность, начинает избавляться от человека. Есть ли крайняя кнопка или возможность у человека отключить всю систему? В целом, наверное, надо подумать над тем, чтобы у нас была возможность обесточить систему или просто деактивировать какое-то решение, принимаемое там, где мы отвлеклись. Но пока все эти страхи вызваны больше результатом научной фантастики и фильмов про будущее…
Есть ли угроза искусственного интеллекта для существующего типа рынка труда? Это естественный цикл осознания принятия решений, когда нам говорят, что вас скорее всего заменят или роботизируют. Это то, с чего все начинают общение с теми, кто приходит им разрабатывать что-то полезное для повышения точности принятия решений и так далее. Но очень быстро становится понятно, когда человек погружается в задачу, что на самом деле это пришли не его автоматизировать, а пришли избавить от рутины, либо существенно повысить производительность тех действий, которые всё ещё требуются от человека, для того, чтобы сделать какой-то сервис, реализовать какое-то решение.
Какой из страхов искусственного интеллекта наиболее реальный? Самая большая опасность – плохая интерпретируемость моделей и их нестабильность. Если модели начинают принимать те решения, которые мы не ожидали. Здесь действительно важно иметь те самые ограничители и системы мониторинга качества моделей.