Cодержание
_____________________________________________________
У вас есть большой набор данных, полный интересных идей, но вы не знаете, с чего начать его изучение? Ваш начальник просил вас собрать из него статистику, но ее не так-то просто извлечь? Это как раз те варианты использования, в которых вам могут помочь Pandas и Python! С помощью этих инструментов вы сможете разделить большой набор данных на управляемые части и извлечь из этой информации понимание.
В этом руководстве вы узнаете, как:
Вы также узнаете о различиях между основными структурами данных, которые используют Pandas и Python. Чтобы продолжить, вы можете получить весь пример кода в этом руководстве по ссылке ниже:
Настройка вашей среды
Для начала работы" с этим руководством вам понадобится несколько вещей. Во-первых, знакомство со встроенными структурами данных Python, особенно списками и словарями. Для получения дополнительной информации ознакомьтесь со списками и кортежами в Python и словарями в Python.
Второе, что вам понадобится, - это рабочая среда Python. Вы можете следить за ним в любом терминале, на котором установлен Python 3. Если вы хотите получить более качественный результат, особенно для большого набора данных NBA, с которым вы будете работать, вы можете запустить примеры в блокноте Jupyter.
Последнее, что вам понадобится, это библиотека Python Pandas, которую вы можете установить с помощью pip:
$ python -m pip install pandas
Вы также можете использовать менеджер пакетов Conda:
$ conda install pandas
Если вы используете дистрибутив Anaconda, то все готово! Anaconda уже поставляется с установленной библиотекой Pandas Python.
Примечание: вы слышали, что в мире Python существует несколько менеджеров пакетов, и не знаете, какой из них выбрать? pip и conda - отличный выбор, и у каждого из них есть свои преимущества.
Если вы собираетесь использовать Python в основном для работы с данными, тогда conda, возможно, станет лучшим выбором. В экосистеме conda есть две основные альтернативы:
Если вы хотите быстро настроить и запустить стабильную среду обработки данных и не возражаете загрузить 500 МБ данных, обратите внимание на дистрибутив Anaconda. Если вы предпочитаете более минималистичную настройку, ознакомьтесь с разделом по установке Miniconda в разделе Настройка Python для машинного обучения в Windows.
Давайте начнем!
Использование библиотеки Python Pandas
Теперь, когда вы установили Pandas, пришло время взглянуть на набор данных. В этом руководстве вы проанализируете результаты NBA, предоставленные FiveThirtyEight, в файле CSV размером 17 МБ. Создайте скрипт download_nba_all_elo.py для загрузки данных:
import requests
download_url = "https://raw.githubusercontent.com/fivethirtyeight/data/master/nba-elo/nbaallelo.csv"
target_csv_path = "nba_all_elo.csv"
response = requests.get(download_url)
response.raise_for_status() # Check that the request was successful
with open(target_csv_path, "wb") as f:
f.write(response.content)
print("Download ready.")
Когда вы выполняете сценарий, он сохранит файл nba_all_elo.csv в вашем текущем рабочем каталоге.
Примечание. Вы также можете использовать свой веб-браузер для загрузки файла CSV.
Однако наличие сценария загрузки дает несколько преимуществВы можете сказать, где вы взяли свои данные. Вы можете повторить загрузку в любое время! Это особенно удобно, если данные часто обновляются. Вам не нужно предоставлять совместный доступ к CSV-файлу размером 17 МБ с коллегами. Обычно достаточно поделиться скриптом загрузки.
Теперь вы можете использовать библиотеку Pandas Python, чтобы просмотреть свои данные:
>>> import pandas as pd
>>> nba = pd.read_csv("nba_all_elo.csv")
>>> type(nba)
<class 'pandas.core.frame.DataFrame'>
Здесь вы следуете соглашению об импорте Pandas в Python с псевдонимом pd. Затем вы используете .read_csv () для чтения в вашем наборе данных и сохраняете его как объект DataFrame в переменной nba.
Вы можете увидеть, сколько данных содержит nba:
>>> len(nba) 126314 >>> nba.shape (126314, 23)
Вы используете встроенную функцию Python len () для определения количества строк. Вы также можете использовать атрибут .shape DataFrame, чтобы увидеть его размерность. Результатом является кортеж, содержащий количество строк и столбцов.
Теперь вы знаете, что в вашем наборе данных 126 314 строк и 23 столбца. Но как вы можете быть уверены, что набор данных действительно содержит статистику баскетбола? Вы можете посмотреть первые пять строк с помощью .head ():
>>> nba.head()
Если вы следите за записной книжкой Jupyter, вы увидите следующий результат:
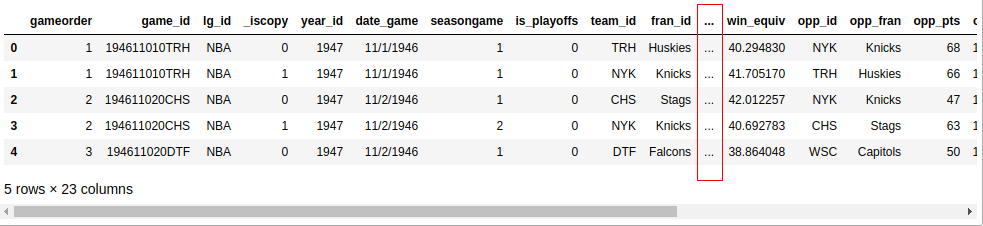
Если ваш экран не очень большой, в вашем выводе, вероятно, не будут отображаться все 23 столбца. Где-то посередине вы увидите столбец из эллипсов (...), указывающий на недостающие данные. Если вы работаете в терминале, это, вероятно, удобнее для чтения, чем перенос длинных строк. Однако записные книжки Jupyter позволяют прокручивать. Вы можете настроить Pandas для отображения всех 23 столбцов следующим образом:
>>> pd.set_option("display.max.columns", None)
Now, you should see all the columns, and your data should show two decimal places:

Подобно стандартной библиотеке Python, функции в Pandas также имеют несколько дополнительных параметров. Всякий раз, когда вы сталкиваетесь с примером, который выглядит релевантным, но немного отличается от вашего варианта использования, просмотрите официальную документацию. Велика вероятность, что вы найдете решение, настроив некоторые дополнительные параметры!
Знакомство с вашими данными
Вы импортировали CSV-файл с библиотекой Pandas Python и впервые ознакомились с содержимым своего набора данных. Пока вы видели только размер вашего набора данных, а также его первые и последние несколько строк. Затем вы узнаете, как более систематически анализировать свои данные.
Отображение типов данных
Первый шаг к знакомству с вашими данными - выявление различных типов данных, которые они содержат. Хотя вы можете поместить что угодно в список, столбцы DataFrame содержат значения определенного типа данных. Когда вы сравните структуры данных Pandas и Python, вы увидите, что такое поведение делает Pandas намного быстрее!
Вы можете отобразить все столбцы и их типы данных с помощью .info ():
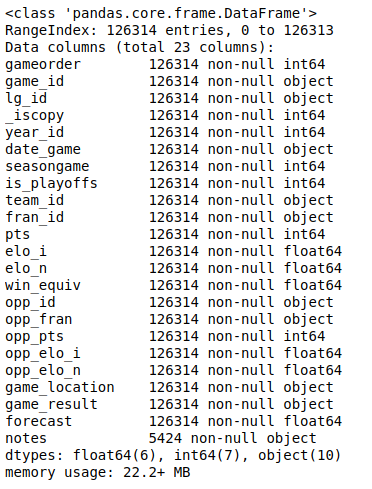
Вы увидите список всех столбцов в наборе данных и типы данных, которые содержит каждый столбец. Здесь вы можете увидеть типы данных int64, float64 и object. Pandas использует библиотеку NumPy для работы с этими типами. Позже вы познакомитесь с более сложным категориальным типом данных, который реализует сама библиотека Pandas Python.
Тип данных объекта - особый. Согласно Поваренной книге Pandas, тип данных объекта является «универсальным для столбцов, которые Pandas не распознает как любой другой конкретный тип». На практике это часто означает, что все значения в столбце являются строками.
Хотя вы можете хранить произвольные объекты Python в типе данных object, вы должны знать о недостатках этого. Странные значения в столбце объекта могут нанести вред производительности Pandas и его совместимости с другими библиотеками. Для получения дополнительной информации ознакомьтесь с официальным руководством по началу работы.
Отображение основной статистики
Теперь, когда вы увидели, какие типы данных содержатся в вашем наборе данных, пора получить обзор значений, содержащихся в каждом столбце. Вы можете сделать это с помощью .describe ():
Эта функция показывает вам базовую описательную статистику для всех числовых столбцов:
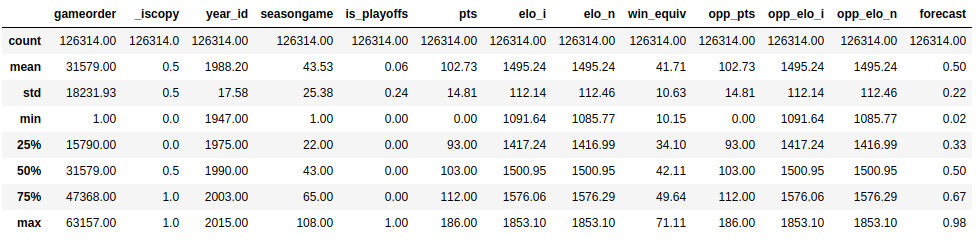
.describe () не будет пытаться вычислить среднее значение или стандартное отклонение для столбцов объекта, поскольку они в основном включают текстовые строки. Тем не менее, он все равно будет отображать некоторую описательную статистику:

Взгляните на столбцы team_id и fran_id. Ваш набор данных содержит 104 разных идентификатора команды, но только 53 разных идентификатора франшизы. Кроме того, наиболее частым идентификатором команды является BOS, но чаще всего - идентификатором франшизы Lakers. Как такое возможно? Чтобы ответить на этот вопрос, вам потребуется еще немного изучить свой набор данных.
Изучение вашего набора данных
Исследовательский анализ данных может помочь вам ответить на вопросы о вашем наборе данных. Например, вы можете проверить, как часто определенные значения встречаются в столбце:
>>> nba["team_id"].value_counts() BOS 5997 NYK 5769 LAL 5078 ... SDS 11 >>> nba["fran_id"].value_counts() Name: team_id, Length: 104, dtype: int64 Lakers 6024 Celtics 5997 Knicks 5769 ... Huskies 60 Name: fran_id, dtype: int64
Кажется, что команда под названием «Лейкерс» провела 6024 игры, но только 5078 из них сыграли «Лос-Анджелес Лейкерс». Узнайте, кто такая другая команда «Лейкерс»:
>>> nba.loc[nba["fran_id"] == "Lakers", "team_id"].value_counts() LAL 5078 MNL 946 Name: team_id, dtype: int64
Похоже, «Миннеаполис Лейкерс» играли с 1949 по 1959 год. Это объясняет, почему вы могли не узнать эту команду!
Вы также узнали, почему команда Boston Celtics "BOS" сыграла больше всего игр в наборе данных. Давайте также немного проанализируем их историю. Узнайте, сколько очков команда Boston Celtics набрала во всех матчах, содержащихся в этом наборе данных. Разверните блок кода ниже для решения:
Similar to the .min() and .max() aggregate functions, you can also use .sum():
>>> nba.loc[nba["team_id"] == "BOS", "pts"].sum() 626484
The Boston Celtics scored a total of 626,484 points.
Вы уже знакомы с возможностями Pandas DataFrame. В следующих разделах вы подробно остановитесь на тех методах, которые только что использовали, но сначала вы увеличите масштаб и узнаете, как работает эта мощная структура данных.
Знакомство со структурами данных Pandas
Хотя DataFrame предоставляет функции, которые могут показаться интуитивно понятными, лежащие в основе концепции немного сложнее понять. По этой причине вы отложите обширный NBA DataFrame и создадите несколько небольших объектов Pandas с нуля.
Понимание объектов серии
Самая основная структура данных Python - это список, который также является хорошей отправной точкой для знакомства с объектами pandas.Series. Создайте новый объект Series на основе списка:
>>> revenues = pd.Series([5555, 7000, 1980]) >>> revenues 0 5555 1 7000 2 1980 dtype: int64
Здесь индекс - это список названий городов, представленных строками. Возможно, вы заметили, что словари Python также используют строковые индексы, и это удобная аналогия, о которой следует помнить! Вы можете использовать приведенные выше блоки кода, чтобы различать два типа серий:
доходы: эта серия ведет себя как список Python, поскольку имеет только позиционный индекс.
city_revenue: Эта серия действует как словарь Python, поскольку содержит как позиционный индекс, так и индекс меток.
Вот как создать серию с индексом метки из словаря Python:
>>> city_employee_count = pd.Series({"Amsterdam": 5, "Tokyo": 8})
>>> city_employee_count
Amsterdam 5
Tokyo 8
dtype: int64
Ключи словаря становятся индексом, а значения словаря - значениями серии.
Как и словари, Series также поддерживает .keys () и ключевое слово in:
Index(['Amsterdam', 'Tokyo'], dtype='object') >>> "Tokyo" in city_employee_count True >>> "New York" in city_employee_count False
Вы можете использовать эти методы, чтобы быстро ответить на вопросы о вашем наборе данных.
Понимание объектов DataFrame
Хотя серия представляет собой довольно мощную структуру данных, у нее есть свои ограничения. Например, вы можете хранить только один атрибут для каждого ключа. Как вы видели на примере набора данных nba, который включает 23 столбца, библиотека Pandas Python может предложить больше с помощью DataFrame. Эта структура данных представляет собой последовательность объектов Series, которые имеют один и тот же индекс.
Если вы следовали примерам серии, то у вас уже должно быть два объекта серии с городами в качестве ключей:
city_revenues city_employee_count
Вы можете объединить эти объекты в DataFrame, предоставив словарь в конструкторе. Ключи словаря станут именами столбцов, а значения должны содержать объекты Series:
>>> city_data = pd.DataFrame({
... "revenue": city_revenues,
... "employee_count": city_employee_count
... })
>>> city_data
revenue employee_count
Amsterdam 4200 5.0
Tokyo 6500 8.0
Toronto 8000 NaN
Вы также можете ссылаться на 2 измерения DataFrame как на оси:
>>> city_data.axes [Index(['Amsterdam', 'Tokyo', 'Toronto'], dtype='object'), Index(['revenue', 'employee_count'], dtype='object')] >>> city_data.axes[0] Index(['Amsterdam', 'Tokyo', 'Toronto'], dtype='object') >>> city_data.axes[1] Index(['revenue', 'employee_count'], dtype='object')
Ось, отмеченная цифрой 0, - это индекс строки, а ось, отмеченная цифрой 1, - индекс столбца. Эту терминологию важно знать, поскольку вы встретите несколько методов DataFrame, которые принимают параметр оси.
DataFrame также является структурой данных, подобной словарю, поэтому он также поддерживает .keys () и ключевое слово in. Однако для DataFrame они относятся не к индексу, а к столбцам:
>>> city_data.keys() Index(['revenue', 'employee_count'], dtype='object') >>> "Amsterdam" in city_data False >>> "revenue" in city_data True
Когда вы используете эти методы для ответа на вопросы о своем наборе данных, не забывайте, работаете ли вы с Series или DataFrame, чтобы ваша интерпретация была точной.
Запрос вашего набора данных
Вы узнали, как получить доступ к подмножествам огромного набора данных на основе его индексов. Теперь вы выберете строки на основе значений в столбцах набора данных для запроса данных. Например, вы можете создать новый DataFrame, содержащий только игры, в которые играли после 2010 года:
>>> current_decade = nba[nba["year_id"] > 2010] >>> current_decade.shape (12658, 23)
Это может быть полезно, если вы хотите избежать пропущенных значений в столбце. Вы также можете использовать .notna () для достижения той же цели.
Вы даже можете получить доступ к значениям типа данных объекта как str и применить к ним строковые методы:
>>> ers = nba[nba["fran_id"].str.endswith("ers")]
>>> ers.shape
(27797, 23)
Вы используете .str.endswith (), чтобы отфильтровать свой набор данных и найти все игры, в которых название домашней команды заканчивается на "ers".
Вы также можете комбинировать несколько критериев и запрашивать свой набор данных. Для этого обязательно заключите каждый из них в круглые скобки и используйте логические операторы | и &, чтобы разделить их.
Примечание: операторы and, or, && и || здесь работать не будет. Если вам интересно, почему, то ознакомьтесь с разделом о том, как библиотека Pandas Python использует логические операторы в Python Pandas: приемы и возможности, о которых вы, возможно, не знаете.
Здесь вы используете nba ["_ iscopy"] == 0, чтобы включить только те записи, которые не являются копиями.
Ваш вывод должен содержать пять насыщенных событиями игр:
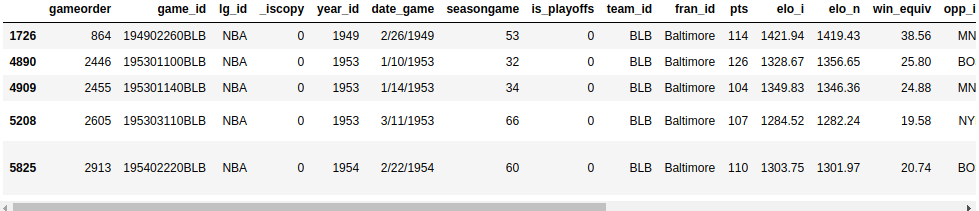
Попробуйте создать другой запрос с несколькими критериями. Весной 1992 года обеим командам из Лос-Анджелеса предстояло провести домашнюю игру на другом корте. Запросите свой набор данных, чтобы найти эти две игры. Обе команды имеют ID, начинающийся с "LA". Разверните блок кода ниже, чтобы увидеть решение:
Вы можете использовать .str, чтобы найти идентификаторы команд, начинающиеся с "LA", и вы можете предположить, что в такой необычной игре будут некоторые примечания:
>>> nba[ ... (nba["_iscopy"] == 0) & ... (nba["team_id"].str.startswith("LA")) & ... (nba["year_id"]==1992) & ... (nba["notes"].notnull()) ... ]Ваш результат должен показать две игры в день 03.05.1992:
Хорошая находка!
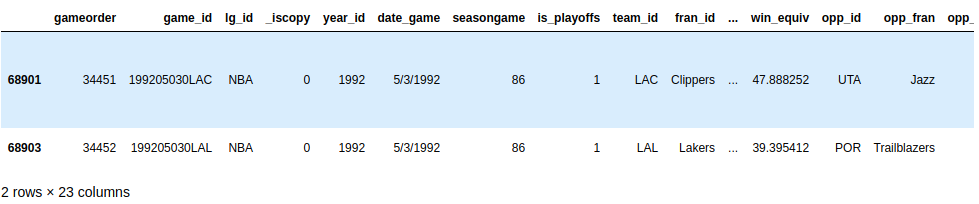
Когда вы знаете, как запрашивать свой набор данных по нескольким критериям, вы сможете ответить на более конкретные вопросы о своем наборе данных.
Указание типов данных
Когда вы создаете новый DataFrame, вызывая конструктор или читая CSV-файл, Pandas назначает тип данных каждому столбцу на основе его значений. Хотя он работает неплохо, он не идеален. Если вы заранее выберете правильный тип данных для столбцов, то сможете значительно улучшить производительность своего кода.
Взглянем еще раз на столбцы набора данных nba:
>>> df.info()
Вы увидите тот же результат, что и раньше:
Какой тип данных вы бы использовали в реляционной базе данных для такого столбца? Вероятно, вы бы использовали не тип varchar, а перечисление. Pandas предоставляет категориальный тип данных для той же цели:
>>> df["game_location"] = pd.Categorical(df["game_location"]) >>> df["game_location"].dtype CategoricalDtype(categories=['A', 'H', 'N'], ordered=False)
categorical data имеют несколько преимуществ перед неструктурированным текстом. Когда вы указываете категориальный тип данных, вы упрощаете проверку и экономите тонну памяти, поскольку Pandas будет использовать только уникальные значения внутри. Чем выше отношение общих значений к уникальным значениям, тем больше вы сэкономите место.
Снова запустите df.info (). Вы должны увидеть, что изменение типа данных game_location с объекта на категориальное уменьшило использование памяти.
Примечание. Категориальный тип данных также дает вам доступ к дополнительным методам через средство доступа .cat. Чтобы узнать больше, ознакомьтесь с официальной документацией.
Часто встречаются наборы данных со слишком большим количеством текстовых столбцов. Важным навыком для специалистов по данным является способность определять, какие столбцы они могут преобразовать в более производительный тип данных.
Найдите минутку, чтобы попрактиковаться в этом сейчас. Найдите другой столбец в наборе данных nba с общим типом данных и преобразуйте его в более конкретный. Вы можете развернуть блок кода ниже, чтобы увидеть одно возможное решение:
game_result может принимать только два разных значения:
>>> df["game_result"].nunique() 2 >>> df["game_result"].value_counts() L 63157 W 63157Вы можете использовать df.info () для проверки использования памяти.
Когда вы работаете с более массивными наборами данных, экономия памяти становится особенно важной. Обязательно помните о производительности, продолжая исследовать свои наборы данных.
Очистка данных
Вы можете быть удивлены, обнаружив этот раздел так поздно в руководстве! Обычно вы критически оцениваете свой набор данных, чтобы исправить какие-либо проблемы, прежде чем переходить к более сложному анализу. Однако в этом руководстве вы будете полагаться на методы, которые вы узнали в предыдущих разделах, чтобы очистить свой набор данных.
Недостающие значения
Вы когда-нибудь задумывались, почему .info () показывает, сколько ненулевых значений содержит столбец? Причина в том, что это жизненно важная информация. Нулевые значения часто указывают на проблему в процессе сбора данных. Они могут сделать несколько методов анализа, например различные типы машинного обучения, трудными или даже невозможными.
Когда вы изучите набор данных nba с помощью nba.info (), вы увидите, что он довольно аккуратный. Только примечания к столбцу содержат нулевые значения для большинства строк:
Теперь итоговый DataFrame содержит все 126 314 игр, но не иногда пустой столбец заметок.
Если для вашего варианта использования есть значимое значение по умолчанию, вы также можете заменить отсутствующие значения на это:
>>> data_with_default_notes = nba.copy() >>> data_with_default_notes["notes"].fillna( ... value="no notes at all", ... inplace=True ... ) >>> data_with_default_notes["notes"].describe() count 126314 unique 232 top no notes at all freq 120890 Name: notes, dtype: object
Здесь вы заполняете пустые строки заметок строкой «никаких заметок».
Недействительные значения могут быть даже более опасными, чем пропущенные значения. Часто вы можете выполнить анализ данных, как и ожидалось, но результаты получаются необычными. Это особенно важно, если ваш набор данных огромен или используется ручной ввод. Недействительные значения часто сложнее обнаружить, но вы можете реализовать некоторые проверки работоспособности с помощью запросов и агрегатов.
Одна вещь, которую вы можете сделать, - это проверить диапазоны ваших данных. Для этого очень удобна функция .describe (). Напомним, что он возвращает следующий результат:
Этот запрос возвращает одну строку:

Похоже, игра была проиграна. В зависимости от вашего анализа вы можете удалить его из набора данных.
Несовместимые значения
Иногда значение само по себе может быть полностью реалистичным, но оно не соответствует значениям в других столбцах. Вы можете определить некоторые критерии запроса, которые являются взаимоисключающими, и убедиться, что они не встречаются вместе.
В наборе данных NBA значения полей pts, opp_pts и game_result должны согласовываться друг с другом. Вы можете проверить это с помощью атрибута .empty:
>>> nba[(nba["pts"] > nba["opp_pts"]) & (nba["game_result"] != 'W')].empty True >>> nba[(nba["pts"] < nba["opp_pts"]) & (nba["game_result"] != 'L')].empty True
К счастью, оба этих запроса возвращают пустой DataFrame.
Будьте готовы к сюрпризам всякий раз, когда вы работаете с необработанными наборами данных, особенно если они были собраны из разных источников или через сложный конвейер. Вы можете увидеть строки, в которых команда набрала больше очков, чем ее противник, но все равно не выиграла - по крайней мере, согласно вашему набору данных! Чтобы избежать подобных ситуаций, обязательно добавьте дополнительные методы очистки данных в свой арсенал Pandas и Python.
Визуализация фрейма данных Pandas
Визуализация данных - одна из тех вещей, которая работает в записной книжке Jupyter намного лучше, чем в терминале, так что вперед и запускайте ее. Если вам нужна помощь в начале работы, ознакомьтесь с Jupyter Notebook: An Introduction.
Включите эту строку, чтобы отображать графики прямо в записной книжке:
>>> %matplotlib inline
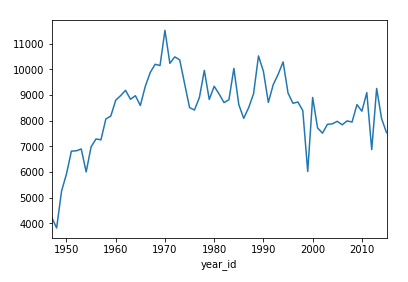
Оба объекта Series и DataFrame имеют метод .plot (), который является оболочкой для matplotlib.pyplot.plot (). По умолчанию он создает линейный график. Визуализируйте, сколько очков набрали «Никс» за сезоны:
>>> nba[nba["fran_id"] == "Knicks"].groupby("year_id")["pts"].sum().plot()
Это показывает линейный график с несколькими пиками и двумя заметными впадинами около 2000 и 2010 годов:
Вы также можете создавать другие типы графиков, например гистограмму:
>>> nba["fran_id"].value_counts().head(10).plot(kind="bar")
Это покажет франшизы с наибольшим количеством сыгранных игр:
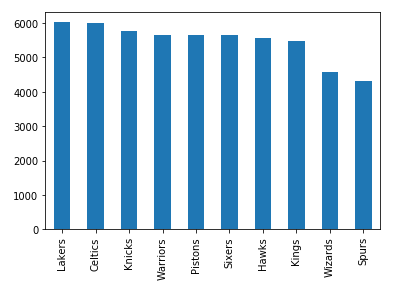
`` Лейкерс '' лидируют в `` Селтикс '' с минимальным преимуществом, и есть еще шесть команд с количеством игр выше 5000.
Теперь попробуйте более сложное упражнение. В 2013 году чемпионат выиграла команда «Майами Хит». Создайте круговую диаграмму, показывающую количество их побед и поражений в этом сезоне. Затем разверните блок кода, чтобы увидеть решение:
Сначала вы определяете критерий, включающий только игры Heat от 2013 года. Затем вы создаете сюжет так же, как вы видели выше:
>>> nba[ ... (nba["fran_id"] == "Heat") & ... (nba["year_id"] == 2013) ... ]["game_result"].value_counts().plot(kind="pie")Вот как выглядит чемпионский пирог:
Срез выигрышей значительно больше, чем срез проигрышей!
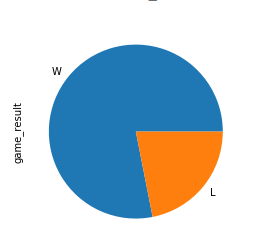
Иногда числа говорят сами за себя, но часто диаграмма очень помогает передать ваши мысли. Чтобы узнать больше о визуализации данных, ознакомьтесь с интерактивной визуализацией данных в Python с боке.
Заключение
В этом руководстве вы узнали, как начать изучение набора данных с помощью библиотеки Python Pandas. Вы видели, как можно получить доступ к определенным строкам и столбцам, чтобы приручить даже самые большие наборы данных. Говоря об укрощении, вы также познакомились с несколькими методами подготовки и очистки данных путем указания типа данных столбцов, работы с пропущенными значениями и т. Д. Вы даже создали запросы, агрегаты и графики на их основе.
Теперь вы можете:
________________________________________________
Это путешествие с использованием статистики NBA лишь поверхностное представление о том, что вы можете делать с библиотекой Pandas Python. Вы можете усилить свой проект с помощью приемов Pandas, изучить методы ускорения Pandas на Python и даже погрузиться глубоко, чтобы увидеть, как Pandas работает за кулисами. Вам предстоит открыть для себя еще множество функций, так что приступайте к работе с наборами данных!
____
Оригинал статьи: Using Pandas and Python to Explore Your Dataset