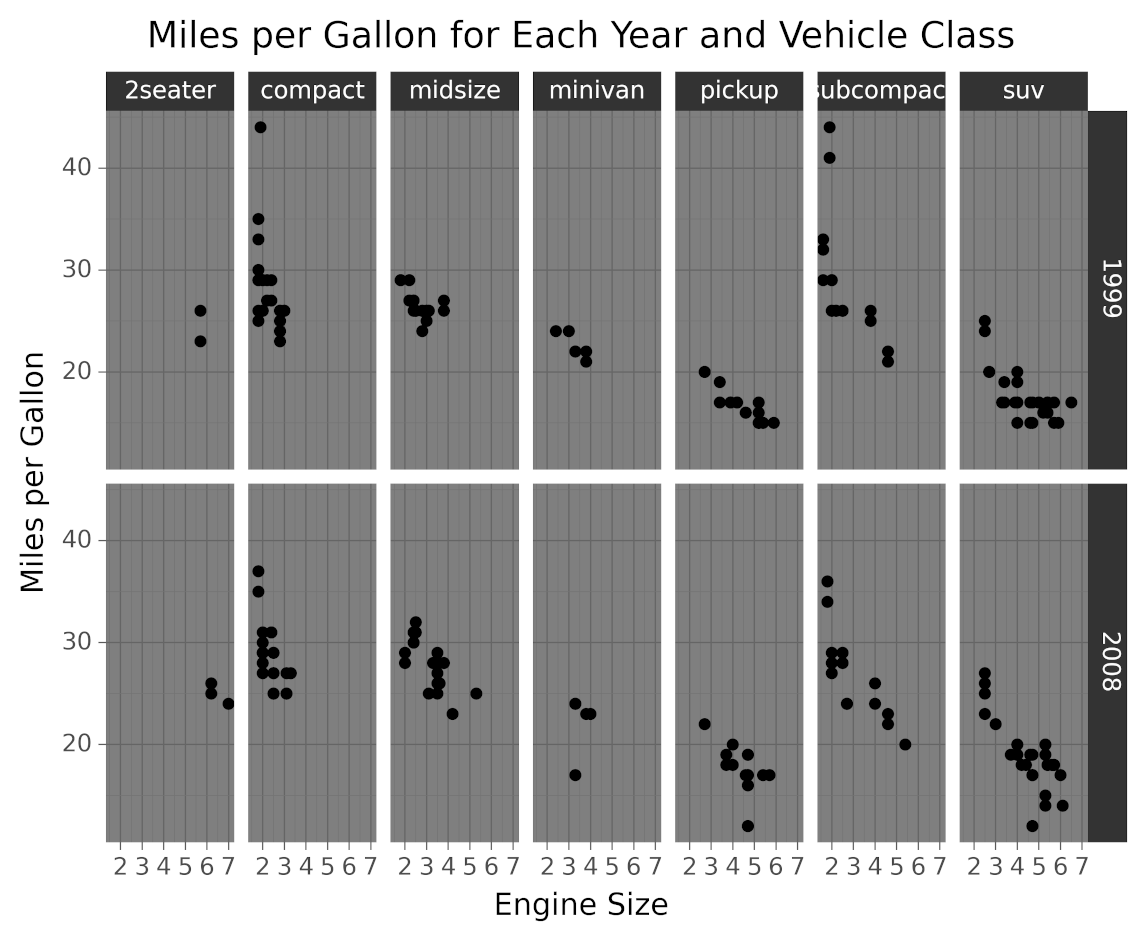
Bokeh гордится тем, что является библиотекой для интерактивной визуализации данных. В отличие от популярных аналогов в области визуализации Python, таких как Matplotlib и Seaborn, Bokeh отображает свою графику с помощью HTML и JavaScript. Это делает его отличным кандидатом для создания веб-панелей и приложений. Тем не менее, это не менее мощный инструмент для изучения и понимания ваших данных или создания красивых пользовательских диаграмм для проекта, или отчета.
Создание первой фигуры
Прежде чем приступить к работе, нам необходимо, соответственно, установить определенные библиотеки, а именно: pandas, numpy и bokeh. Всего есть несколько способов сделать инфографику в Bokeh:
1.output_file(‘filename.html’) - запишет инфографику в статический HTML-файл.
2.output_notebook() - отобразит инфографику непосредственно в Jupyter Notebook.
Важно отметить, что ни одна из функций не отображает визуализацию. Этого не произойдет, пока не будет вызвана функция show(). Однако они гарантируют, что при вызове show() визуализация появится там, где вы хотите. И так как я буду работать в привычном для меня PyCharm, то я буду использовать первый способ. Давайте же создадим первую фигуру:
from bokeh.io import output_file
from bokeh.plotting import figure, show
# Рисунок будет отображен в статическом HTML-файле
output_file('Создание_первой_фигуры.html',
title='Empty Bokeh Figure')
# Настроить общий объект figure()
fig = figure()
# Посмотрите, как это выглядит
show(fig)
Результат:
Как видите, новое окно браузера открылось с вкладкой под названием Empty Bokeh Figure и пустой фигурой, а сам созданный файл с именем «Создание_первой_фигуры.html» появился в папке с проектом.
Подготовка фигуры к данным
Теперь, когда вы знаете, как создавать и просматривать общую фигуру Bokeh в браузере, пора узнать больше о том, как настроить объект figure(). Объект figure() — это не только основа визуализации данных, но и объект, который открывает все доступные инструменты Bokeh для инфографики. Figure Bokeh является подклассом объекта Bokeh Plot, который предоставляет многие параметры, которые позволяют настраивать эстетические элементы инфографики. Чтобы вы могли получить представление о доступных параметрах настройки, давайте создадим самую уродливую инфографика на свете:
from bokeh.plotting import figure, show
output_file('Подготовка_фигуры_к_данным.html',
title='Bokeh Figure')
fig = figure(background_fill_color='gray',
background_fill_alpha=0.5,
border_fill_color='blue',
border_fill_alpha=0.25,
plot_height=300,
plot_width=500,
x_axis_label='X Label',
x_axis_type='datetime',
x_axis_location='above',
x_range=('2018-01-01', '2018-06-30'),
y_axis_label='Y Label',
y_axis_type='linear',
y_axis_location='left',
y_range=(0, 100),
title='Example Figure',
title_location='right',
toolbar_location='below',
tools='save')
show(fig)
Результат:
Рисование данных с помощью глифов
Пустая фигура не так уж и интересна, поэтому давайте посмотрим на глифы. Глиф — это векторизованная графическая форма или маркер, который используется для представления ваших данных в виде круга или квадрата. Начнем с очень простого примера, нарисовав несколько точек на координатной сетке x-y:
#РИСОВАНИЕ ДАННЫХ С ПОМОЩЬЮ ГЛИФОВ
#Создание первых данных
from bokeh.io import output_file
from bokeh.plotting import figure, show
# Мои данные о координатах x-y
x = [1, 2, 1]
y = [1, 1, 2]
output_file('Рисование_данных_с_помощью_глифов1.html', title='First Glyphs')
# Создайте фигуру без панели инструментов и диапазонов осей
fig = figure(title='My Coordinates',
plot_height=300, plot_width=300,
x_range=(0, 3), y_range=(0, 3),
toolbar_location=None)
# Нарисуйте координаты в виде кругов
fig.circle(x=x, y=y,
color='green', size=10, alpha=0.5)
# Показать сюжет
show(fig)
Результат:
Как только ваша фигура будет создана, вы сможете увидеть, как ее можно использовать для рисования данных координат x-y с использованием настраиваемых круговых глифов. Помимо этого, глифы можно комбинировать по мере необходимости, чтобы соответствовать вашим потребностям в визуализации. Допустим, я хочу создать визуализацию, которая показывает, сколько слов я написал за день, чтобы сделать этот руководство, с наложенной линией тренда совокупного количества слов:
#Создание вторых данных
import numpy as np
from bokeh.plotting import figure, show
# Мои данные о подсчете слов
day_num = np.linspace(1, 10, 10)
daily_words = [450, 628, 488, 210, 287, 791, 508, 639, 397, 943]
cumulative_words = np.cumsum(daily_words)
output_file('Рисование_данных_с_помощью_глифов2.html', title='First Glyphs')
# Создаем фигуру с осью x типа datetime
fig = figure(title='My Tutorial Progress',
plot_height=400, plot_width=700,
x_axis_label='Day Number', y_axis_label='Words Written',
x_minor_ticks=2, y_range=(0, 6000),
toolbar_location=None)
# Ежедневные слова будут представлены в виде вертикальных полос (столбцов)
fig.vbar(x=day_num, bottom=0, top=daily_words,
color='blue', width=0.75,
legend='Daily')
# Накопленная сумма будет линией тренда
fig.line(x=day_num, y=cumulative_words,
color='gray', line_width=1,
legend='Cumulative')
# Поместите легенду в левый верхний угол
fig.legend.location = 'top_left'
# Давайте проверим
show(fig)
Результат:
Чтобы объединить столбцы и линии на рисунке, они просто создаются с использованием одного и того же объекта figure (). Кроме того, вы можете увидеть выше, как легко можно создать легенду, задав свойство легенды для каждого глифа. Затем легенда была перемещена в верхний левый угол графика путем присвоения ‘top_left’ значению fig.legend.location.
Небольшая заметка о данных
Каждый раз, когда вы изучаете новую библиотеку визуализации, рекомендуется начинать с некоторых данных из знакомой вам области. Поэтому, в остальных примерах будут использоваться общедоступные данные из Kaggle, который содержит информацию о сезоне 2017-18 Национальной баскетбольной ассоциации (НБА), а именно:
•2017-18_playerBoxScore.csv: снимки статистики игроков по играм;
•2017-18_teamBoxScore.csv: снимки статистики команд по играм;
•2017-18_standings.csv: ежедневное командное положение и рейтинги.
Эти файлы я, соответственно, скачал и разместил в папку с проектом. После чего, они были прочитаны с помощью Pandas DataFrame, используя следующие команды:
import pandas as pd
# Прочитать csv файлы
player_stats = pd.read_csv('2017-18_playerBoxScore.csv', parse_dates=['gmDate'])
team_stats = pd.read_csv('2017-18_teamBoxScore.csv', parse_dates=['gmDate'])
standings = pd.read_csv('2017-18_standings.csv', parse_dates=['stDate'])
print(player_stats)
Этот фрагмент кода считывает данные из трех файлов CSV и автоматически интерпретирует столбцы даты как объекты datetime. Ну и print был применен для того, чтобы проверить, что он выведет, да и считывает ли данные в целом или нет. Результат:
Использование объекта ColumnDataSource
В приведенных выше примерах для представления данных использовались списки Python и массивы Numpy и Bokeh хорошо оснащено для обработки этих типов данных. Однако, когда дело доходит до данных в Python, вы, скорее всего, встретите словари Python и Pandas DataFrames, особенно если вы читаете данные из файла или внешнего источника данных. Bokeh хорошо оснащен для работы с этими более сложными структурами данных и даже имеет встроенные функции для их обработки, а именно ColumnDataSource. Вы можете спросить себя: «Зачем использовать ColumnDataSource, если Bokeh может напрямую взаимодействовать с другими типами данных?» Во-первых, ссылаетесь ли вы напрямую на список, массив, словарь или DataFrame, Bokeh за кулисами все равно превратит его в ColumnDataSource. Что еще более важно, ColumnDataSource значительно упрощает реализацию интерактивных возможностей Bokeh. ColumnDataSource лежит в основе передачи данных глифам, которые вы используете для визуализации.Его основная функция — отображать имена столбцам ваших данных. Это упрощает использование ссылок на элементы данных при построении визуализации. Это также упрощает то же самое для Bokeh при создании визуализации. Давайте начнем с визуализации гонки за первое место в Западной конференции НБА в 2017–2018 годах между действующим чемпионом Golden State Warriors и претендентом Houston Rockets. Ежедневные записи о победах и поражениях этих двух команд хранятся в DataFrame с именем west_top_2:
#ИСПОЛЬЗОВАНИЕ ОБЪЕКТА ColumnDataSource
#Пример 1
west_top_2 = (standings[(standings['teamAbbr'] == 'HOU') | (standings['teamAbbr'] == 'GS')]
.loc[:, ['stDate', 'teamAbbr', 'gameWon']]
.sort_values(['teamAbbr','stDate']))
print(west_top_2.head())
Результат:
Отсюда вы можете загрузить этот DataFrame в два объекта ColumnDataSource и визуализировать гонку:
from bokeh.plotting import figure, show
from bokeh.io import output_file
from bokeh.models import ColumnDataSource
# Output to file
output_file('west-top-2-standings-race1.html',
title='Western Conference Top 2 Teams Wins Race')
# Isolate the data for the Rockets and Warriors
rockets_data = west_top_2[west_top_2['teamAbbr'] == 'HOU']
warriors_data = west_top_2[west_top_2['teamAbbr'] == 'GS']
# Create a ColumnDataSource object for each team
rockets_cds = ColumnDataSource(rockets_data)
warriors_cds = ColumnDataSource(warriors_data)
# Create and configure the figure
fig = figure(x_axis_type='datetime',
plot_height=300, plot_width=600,
title='Western Conference Top 2 Teams Wins Race, 2017-18',
x_axis_label='Date', y_axis_label='Wins',
toolbar_location=None)
# Render the race as step lines
fig.step('stDate', 'gameWon',
color='#CE1141', legend='Rockets',
source=rockets_cds)
fig.step('stDate', 'gameWon',
color='#006BB6', legend='Warriors',
source=warriors_cds)
# Move the legend to the upper left corner
fig.legend.location = 'top_left'
# Show the plot
show(fig)
Результат:
Обратите внимание на ссылки на соответствующие объекты ColumnDataSource при создании двух строк. Вы просто передаете исходные имена столбцов в качестве входных параметров и указываете, какой ColumnDataSource использовать через свойство источника. Визуализация показывает напряженную гонку на протяжении всего сезона, Warriors создают довольно большую подушку в середине сезона. Тем не менее, небольшой спад в конце сезона позволил Rockets наверстать упущенное и в конечном итоге превзойти защищающихся чемпионов и завершить сезон посевным номером один в Западной конференции.
В предыдущем примере были созданы два объекта ColumnDataSource, по одному из подмножества фрейма данных west_top_2. В следующем примере будет воссоздан тот же вывод из одного ColumnDataSource на основе всего west_top_2 с использованием GroupFilter, который создает представление для данных:
#Пример 2
from bokeh.plotting import figure, show
from bokeh.io import output_file
from bokeh.models import ColumnDataSource, CDSView, GroupFilter
# Вывод в файл
output_file('west-top-2-standings-race2.html',
title='Western Conference Top 2 Teams Wins Race')
# Создать ColumnDataSource
west_cds = ColumnDataSource(west_top_2)
# Создайте представления для каждой команды
rockets_view = CDSView(source=west_cds,
filters=[GroupFilter(column_name='teamAbbr', group='HOU')])
warriors_view = CDSView(source=west_cds,
filters=[GroupFilter(column_name='teamAbbr', group='GS')])
# Создаем и настраиваем фигуру
west_fig = figure(x_axis_type='datetime',
plot_height=300, plot_width=600,
title='Western Conference Top 2 Teams Wins Race, 2017-18',
x_axis_label='Date', y_axis_label='Wins',
toolbar_location=None)
# Отрисовываем гонку в виде ступенчатых линий
west_fig.step('stDate', 'gameWon',
source=west_cds, view=rockets_view,
color='#CE1141', legend='Rockets')
west_fig.step('stDate', 'gameWon',
source=west_cds, view=warriors_view,
color='#006BB6', legend='Warriors')
# Переместите легенду в верхний левый угол
west_fig.legend.location = 'top_left'
# Показать сюжет
show(west_fig)
Результат:
Обратите внимание, как GroupFilter передается в CDSView в виде списка. Это позволяет вам комбинировать несколько фильтров вместе, чтобы при необходимости изолировать нужные данные от ColumnDataSource.
Организация нескольких визуализаций с помощью макетов
В турнирной таблице Восточной конференции в Атлантическом дивизионе остались два соперника: Boston Celtics и Toronto Raptors. Прежде чем повторить шаги, использованные для создания west_top_2, давайте попробуем еще раз протестировать ColumnDataSource, используя то, что вы узнали выше. В этом примере вы увидите, как передать весь DataFrame в ColumnDataSource и создать представления для изоляции соответствующих данных:
#ОРГАНИЗАЦИЯ НЕСКОЛЬКИХ ВИЗУАЛИЗАЦИЙ С ПОМОЩЬЮ МАКЕТОВ
from bokeh.plotting import figure, show
from bokeh.io import output_file
from bokeh.models import ColumnDataSource, CDSView, GroupFilter
# Вывод в файл
output_file('Организация_нескольких_визуализаций_с_помощью_макетов.html',
title='Eastern Conference Top 2 Teams Wins Race')
# Создать ColumnDataSource
standings_cds = ColumnDataSource(standings)
# Create views for each team
celtics_view = CDSView(source=standings_cds,
filters=[GroupFilter(column_name='teamAbbr',
group='BOS')])
raptors_view = CDSView(source=standings_cds,
filters=[GroupFilter(column_name='teamAbbr',
group='TOR')])
# Создаем и настраиваем фигуру
east_fig = figure(x_axis_type='datetime',
plot_height=300, plot_width=600,
title='Eastern Conference Top 2 Teams Wins Race, 2017-18',
x_axis_label='Date', y_axis_label='Wins',
toolbar_location=None)
# Отрисовываем гонку в виде ступенчатых линий
east_fig.step('stDate', 'gameWon',
color='#007A33', legend='Celtics',
source=standings_cds, view=celtics_view)
east_fig.step('stDate', 'gameWon',
color='#CE1141', legend='Raptors',
source=standings_cds, view=raptors_view)
# Переместите легенду в верхний левый угол
east_fig.legend.location = 'top_left'
# Показать сюжет
show(east_fig)
Результат:
Добавление взаимодействия
Выбор точек данных
Реализовать поведение выбора так же просто, как добавить несколько конкретных ключевых слов при объявлении ваших глифов. В следующем примере создается диаграмма разброса, которая связывает общее количество попыток трехочковых бросков игроком с их процентом (для игроков, сделавших не менее 100 трехочковых бросков). Данные могут быть агрегированы из DataFrame player_stats:
#ДОБАВЛЕНИЕ ВЗАИМОДЕЙСТВИЯ
#ВЫБОР ТОЧЕК ДАННЫХ
# Найдите игроков, которые сделали хотя бы 1 трехочковый бросок за сезон
three_takers = player_stats[player_stats['play3PA'] > 0]
# Убрать имена игроков, поместив их в один столбец
three_takers['name'] = [f'{p["playFNm"]} {p["playLNm"]}'
for _, p in three_takers.iterrows()]
# Суммируйте общее количество трехочковых попыток и количество попыток для каждого игрока
three_takers = (three_takers.groupby('name')
.sum()
.loc[:,['play3PA', 'play3PM']]
.sort_values('play3PA', ascending=False))
# Отфильтровать всех, кто не сделал хотя бы 100 трехочковых бросков
three_takers = three_takers[three_takers['play3PA'] >= 100].reset_index()
# Добавить столбец с рассчитанным трехбалльным процентом (выполнено / предпринято)
three_takers['pct3PM'] = three_takers['play3PM'] / three_takers['play3PA']
print(three_takers.sample(5))
Результат:
Допустим, вы хотите выбрать группы игроков в раздаче и при этом отключить цвет глифов, представляющих невыбранных игроков:
# Выбор группы игроков в раздаче из полученного DataFrame, при этом отключить цвет глифов
from bokeh.plotting import figure, show
from bokeh.io import output_file
from bokeh.models import ColumnDataSource, NumeralTickFormatter
# Файл вывода
output_file('Выбор_точек_данных.html',
title='Three-Point Attempts vs. Percentage')
# Сохраним данные в ColumnDataSource
three_takers_cds = ColumnDataSource(three_takers)
# Укажите инструменты выбора, которые будут доступны
select_tools = ['box_select', 'lasso_select', 'poly_select', 'tap', 'reset']
# Создание картинки
fig = figure(plot_height=400,
plot_width=600,
x_axis_label='Three-Point Shots Attempted',
y_axis_label='Percentage Made',
title='3PT Shots Attempted vs. Percentage Made (min. 100 3PA), 2017-18',
toolbar_location='below',
tools=select_tools)
# Отформатируйте метки делений оси Y в процентах
fig.yaxis[0].formatter = NumeralTickFormatter(format='00.0%')
# Добавить квадрат, представляющий каждого игрока
fig.square(x='play3PA',
y='pct3PM',
source=three_takers_cds,
color='royalblue',
selection_color='deepskyblue',
nonselection_color='lightgray',
nonselection_alpha=0.3)
# Показать результат
show(fig)
Сначала укажите инструменты выбора, которые вы хотите сделать доступными. В приведенном выше примере «box_select», «lasso_select», «poly_select» и «tap» (плюс кнопка сброса) были указаны в списке под названием select_tools. Когда фигура создается, панель инструментов располагается «below» («ниже») графика, и список передается в инструменты, чтобы сделать инструменты, выбранные выше, доступными. Каждый игрок изначально представлен синим квадратным глифом, но при выборе игрока или группы игроков устанавливаются следующие конфигурации:
• Превратите выбранных игроков в темно-синий
• Измените глифы всех невыделенных игроков на светло-серый цвет с непрозрачностью 0,3
Результат:
Добавление действий при наведении курсора
Таким образом, реализована возможность выбора конкретных точек данных игроков, которые кажутся интересными на моем графике разброса, но что, если вы хотите быстро увидеть, каких отдельных игроков представляет глиф? Один из вариантов — использовать Bokeh HoverTool (), чтобы показывать всплывающую подсказку, когда курсор пересекает пути с глифом. Все, что вам нужно сделать, это добавить в приведенный выше фрагмент кода следующее:
#ДОБАВЛЕНИЕ ДЕЙСТВИЙ ПРИ НАВЕДЕНИИ КУРСОРА
from bokeh.models import HoverTool
output_file('Добавление_действий_при_наведении_курсора.html',
title='Three-Point Attempts vs. Percentage')
# Отформатируйте всплывающую подсказку
# Отформатируйте всплывающую подсказку
tooltips = [
('Player','@name'),
('Three-Pointers Made', '@play3PM'),
('Three-Pointers Attempted', '@play3PA'),
('Three-Point Percentage','@pct3PM{00.0%}'),
]
# Настроить рендерер, который будет использоваться при наведении
hover_glyph = fig.circle(x='play3PA', y='pct3PM', source=three_takers_cds,
size=15, alpha=0,
hover_fill_color='black', hover_alpha=0.5)
# Добавляем HoverTool к фигуре
fig.add_tools(HoverTool(tooltips=tooltips, renderers=[hover_glyph]))
# Показать
show(fig)
HoverTool() немного отличается от инструментов выбора, которые вы видели выше, тем, что у него есть свойства, в частности всплывающие подсказки. Во-первых, вы можете настроить отформатированную всплывающую подсказку, создав список кортежей, содержащих описание и ссылку на ColumnDataSource. Этот список был передан в качестве входных данных в HoverTool(), а затем просто добавлен к рисунку с помощью add_tools(). Для большего подчеркивания игроков при наведении, был создан новый глиф, в данном случае кружков вместо квадратов, и присвоения ему hover_glyph. Обратите внимание, что начальная непрозрачность установлена на ноль, поэтому она невидима, пока курсор не коснется ее. Свойства, которые появляются при наведении курсора, фиксируются путем установки hover_alpha значения 0,5 вместе с hover_fill_color. Теперь вы увидите, как маленький черный кружок появляется над исходным квадратом при наведении курсора на различные маркеры. Вот что произошло:
Выделение данных с помощью легенды
В этом примере вы увидите две идентичные диаграммы разброса, на которых сравниваются игровые очки и подборы Леброна Джеймса и Кевина Дюранта. Единственная разница будет заключаться в том, что один будет использовать hide в качестве своей click_policy, а другой — mute. Первый шаг — настроить вывод и настроить данные, создав представление для каждого игрока из кадра данных player_stats:
#ВЫДЕЛЕНИЕ ДАННЫХ С ПОМОЩЬЮ ЛЕГЕНДЫ
from bokeh.plotting import figure, show
from bokeh.io import output_file
from bokeh.models import ColumnDataSource, CDSView, GroupFilter
from bokeh.layouts import row
# Вывести в записной книжке
output_file('lebron-vs-durant.html',
title='LeBron James vs. Kevin Durant')
# Хранить данные в ColumnDataSource
player_gm_stats = ColumnDataSource(player_stats)
# Создайте представление для каждого игрока
lebron_filters = [GroupFilter(column_name='playFNm', group='LeBron'),
GroupFilter(column_name='playLNm', group='James')]
lebron_view = CDSView(source=player_gm_stats,
filters=lebron_filters)
durant_filters = [GroupFilter(column_name='playFNm', group='Kevin'),
GroupFilter(column_name='playLNm', group='Durant')]
durant_view = CDSView(source=player_gm_stats,
filters=durant_filters)
Перед созданием рисунков общие параметры рисунка, маркеры и данные могут быть объединены в словари и повторно использованы. Это не только сохраняет избыточность на следующем шаге, но и предоставляет простой способ настроить эти параметры позже, если потребуется:
# Объединить общие аргументы ключевых слов в dicts
common_figure_kwargs = {
'plot_width': 400,
'x_axis_label': 'Points',
'toolbar_location': None,
}
common_circle_kwargs = {
'x': 'playPTS',
'y': 'playTRB',
'source': player_gm_stats,
'size': 12,
'alpha': 0.7,
}
common_lebron_kwargs = {
'view': lebron_view,
'color': '#002859',
'legend': 'LeBron James'
}
common_durant_kwargs = {
'view': durant_view,
'color': '#FFC324',
'legend': 'Kevin Durant'
}
Теперь, когда различные свойства установлены, два графика разброса можно построить гораздо более кратко:
# Создайте две фигуры и нарисуйте данные
hide_fig = figure(**common_figure_kwargs,
title='Click Legend to HIDE Data',
y_axis_label='Rebounds')
hide_fig.circle(**common_circle_kwargs, **common_lebron_kwargs)
hide_fig.circle(**common_circle_kwargs, **common_durant_kwargs)
mute_fig = figure(**common_figure_kwargs, title='Click Legend to MUTE Data')
mute_fig.circle(**common_circle_kwargs, **common_lebron_kwargs,
muted_alpha=0.1)
mute_fig.circle(**common_circle_kwargs, **common_durant_kwargs,
muted_alpha=0.1)
Обратите внимание, что у mute_fig есть дополнительный параметр под названием muted_alpha. Этот параметр управляет непрозрачностью маркеров, когда отключение звука используется как click_policy. Наконец, устанавливается click_policy для каждой фигуры, и они отображаются в горизонтальной конфигурации:
# Добавляем интерактивности в легенду
hide_fig.legend.click_policy = 'hide'
mute_fig.legend.click_policy = 'mute'
# Визуализировать
show(row(hide_fig, mute_fig))
Результат:
После того, как легенда размещена, все, что вам нужно сделать, это назначить либо скрыть, либо отключить для свойства фигуры click_policy. Это автоматически превратит вашу базовую легенду в интерактивную легенду. Также обратите внимание, что специально для отключения звука дополнительное свойство muted_alpha было установлено в соответствующих круговых глифах для Леброна Джеймса и Кевина Дюранта. Это определяет визуальный эффект, обусловленный взаимодействием легенды.