Сканер поддоменов на Python
Обнаружение поддоменов определенного веб-сайта позволяет изучить всю его доменную инфраструктуру. Что это вообще такое? Домен — это адрес сайта в интернете, а поддомен — это домен, который является частью домена более высокого уровня. Для более лучшего понимания, например, у нас есть квартира, которую хозяин, после заселения, решил разделить на отдельные зоны. (для сна, отдыха, питания и так далее) И вся квартира будет выступать у нас в качестве домена, а эти функциональные зоны – поддомены. Если искать их вручную, то на это уйдет целая вечность. Но к счастью, можно написать программу на Python, которая будет делать это за нас, используя метод полного перебора, суть которого состоит в проверке всех общих имен поддоменов конкретного домена, всякий раз, когда мы получаем ответ от сервера, то есть - индикатор того, что поддомен жив. И в данной работе, я исследую сайт GitHub.
Первым делом, нам понадобится установить библиотеку requests, с помощью команды: pip3 install requests, после чего написать код, в котором мы ее импортируем и указываем домен для поиска поддоменов:
import requests
# домен для поиска поддоменов
domain = "github.com"
Далее, я использовал текстовый файл “subdomains-1000.txt”, содержащий список из 1000 поддоменов, наличие которых мы хотим проверить. Его я закинул в папку с моим проектом, после чего был написан следующий код:
# читать все поддомены
file = open("subdomains-1000.txt")
# прочитать весь контент
content = file.read()
# разделить на новые строки
subdomains = content.splitlines()
# список обнаруженных поддоменов
discovered_subdomains = []
for subdomain in subdomains:
# создать URL
url = f"http://{subdomain}.{domain}"
try:
# если возникает ОШИБКА, значит, субдомен не существует
requests.get(url)
except requests.ConnectionError:
# если поддомена не существует, просто передать, ничего не выводить
pass
else:
print("[+] Обнаружен поддомен:", url)
# добавляем обнаруженный поддомен в наш список
discovered_subdomains.append(url)
В нем мы создаем URL-адрес, подходящий для отправки запроса, затем мы используем функцию requests.get() для получения HTTP-ответа от сервера, что вызовает исключение ConnectionError всякий раз, когда сервер не отвечает, поэтому мы обернули это в блоке try/except. Если же исключение не возникло, значит субдомен существует. Запишем все обнаруженные поддомены в файл:
# сохраняем обнаруженные поддомены в файл
with open("discovered_subdomains.txt", "w") as f:
for subdomain in discovered_subdomains:
print(subdomain, file=f)
Как только процесс поиска будет завершен, вы увидите новый файл discover_subdomains.txt, который включает все обнаруженные поддомены.
Автоматизация процесса входа на какой-либо веб-сайт, используя программу, написанную на Python, очень удобна и практична в эксплуатации. Реализовывается это благодаря библиотеке Selenium WebDriver. Selenium WebDriver — это библиотека для управления браузером, которая поддерживает все основные браузеры и доступна для разных языков программирования, включая Python. И в данной работе я бы хотел использовать ее для автоматизированного входа на GitHub.
Первым делом, что нам необходимо сделать – это установить Selenium для Python, использую команду: pip3 install selenium. После этого, понадобится установить специфичный драйвер для браузера, которым мы хотим управлять. Лично я, буду использовать ChromeDriver, но вы можете использовать любой другой. Далее, необходимо открыть новый скрипт Python, инициализировать WebDriver и ввести свои учетные данные от GitHub:
from selenium import webdriver
from selenium.webdriver.support.ui import WebDriverWait
# Github credentials
username = "username"
password = "password"
# initialize the Chrome driver
driver = webdriver.Chrome("chromedriver")
После того, как мы загрузили и разархивировали драйвер, необходимо будет его поместить в текущий каталог, то есть, скачанный мною chromedriver.exe я помещаю в папку с проектом. Именно поэтому, я просто передаю его имя конструктору.
Поскольку мы заинтересованы в автоматизации входа в систему GitHub, то перейдем на страницу входа в Github и посмотрим на неё через кнопку f12 для того, чтобы найти её HTML элементы, а именно: идентификатор полей ввода логина и пароля, а также имя кнопки входа, необходимые для получения этих элементов в коде и их запрограммирования. Обратите внимание, что поле ввода имени пользователя/адреса электронной почты имеет id поля login_field, где поле ввода пароля имеет id password. Также кнопка отправки имеет имя commit. И приведенный ниже код переходит на страницу входа в Github, извлекает эти элементы, заполняет учетные данные и нажимает кнопку:
# перейти на страницу входа в github
driver.get("https://github.com/login")
# найти поле имени пользователя / электронной почты и отправить само имя пользователя в поле ввода
driver.find_element_by_id("login_field").send_keys(username)
# найти поле ввода пароля и также вставить пароль
driver.find_element_by_id("password").send_keys(password)
# нажмите кнопку входа в систему
driver.find_element_by_name("commit").click()
В данном коде, функция find_element_by_id() извлекает HTML элемент по его идентификатору, а метод send_keys() имитирует нажатие клавиш. Приведенный выше код заставит Chrome ввести электронное письмо и пароль, а затем нажать кнопку «Sign in».
Следующее, что нужно сделать, это определить, был ли наш вход в систему успешным. Для этого есть масса способов, но здесь мы попытаемся обнаружить ошибку при входе в систему. С помощью все той же консоли, которая вызывается клавишей f12, мы увидим, что при непрвильном вводе учетных данных, появляется новый элемент div HTML с классом «flash-error», который имеет текст «Incorrect username or password» («Неправильное имя пользователя или пароль»). Приведенный ниже код отвечает за ожидание загрузки страницы после входа в систему с помощью WebDriverWait() и проверяет наличие ошибки:
# ждем завершения состояния готовности
WebDriverWait(driver=driver, timeout=10).until(
lambda x: x.execute_script("return document.readyState === 'complete'")
)
error_message = "Incorrect username or password."
# получаем ошибки (если есть)
errors = driver.find_elements_by_class_name("flash-error")
# при необходимости распечатать ошибки
# для e в ошибках:
# print(e.text)
# если мы находим это сообщение об ошибке в составе error, значит вход не выполнен
if any(error_message in e.text for e in errors):
print("[!] Login failed")
else:
print("[+] Login successful")
Тут мы используем WebDriverWait, чтобы дождаться завершения загрузки документа, метод execute_script() выполняет Javascript в браузере, код JS возвращает document.readyState === 'complete' возвращает True, если всё хорошо и False в противном случае.
В результате всех этих действий мы получаем очень удобную программу, которая упрощает нам жизнь. Например, мы написали какую-либо программу на Python и хотим ее выгрузить на наш GitHub. И раньше, чтобы это сделать, необходимо было заходить в браузер, переходить на сайт, вводить свои учетные данные и после этого уже загружать свой новый проект в репозиторий. Теперь же, достаточно просто запустить эту программу, и она все основные действия сделает за вас, вам останется лишь загрузить свой проект.
Для того чтобы читать электронные письма, можно использовать вот этот код:
import imaplib
import email
from email.header import decode_header
import webbrowser
import os
# учетные данные
username = ""
password = "password"
def clean(text):
# чистый текст для создания папки
return "".join(c if c.isalnum() else "_" for c in text)
# create an IMAP4 class with SSL
imap = imaplib.IMAP4_SSL("imap.gmail.com")
# authenticate
imap.login(username, password)
status, messages = imap.select("INBOX")
# количество популярных писем для получения
N = 1
# общее количество писем
messages = int(messages[0])
for i in range(messages, messages-N, -1):
# fetch the email message by ID
res, msg = imap.fetch(str(i), "(RFC822)")
for response in msg:
if isinstance(response, tuple):
# parse a bytes email into a message object
msg = email.message_from_bytes(response[1])
# decode the email subject
subject, encoding = decode_header(msg["Subject"])[0]
if isinstance(subject, bytes):
# if it's a bytes, decode to str
subject = subject.decode(encoding)
# decode email sender
From, encoding = decode_header(msg.get("From"))[0]
if isinstance(From, bytes):
From = From.decode(encoding)
print("Subject:", subject)
print("From:", From)
# if the email message is multipart
if msg.is_multipart():
# iterate over email parts
for part in msg.walk():
# extract content type of email
content_type = part.get_content_type()
content_disposition = str(part.get("Content-Disposition"))
try:
# get the email body
body = part.get_payload(decode=True).decode()
except:
pass
if content_type == "text/plain" and "attachment" not in content_disposition:
# print text/plain emails and skip attachments
print(body)
elif "attachment" in content_disposition:
# download attachment
filename = part.get_filename()
if filename:
folder_name = clean(subject)
if not os.path.isdir(folder_name):
# make a folder for this email (named after the subject)
os.mkdir(folder_name)
filepath = os.path.join(folder_name, filename)
# download attachment and save it
open(filepath, "wb").write(part.get_payload(decode=True))
else:
# extract content type of email
content_type = msg.get_content_type()
# get the email body
body = msg.get_payload(decode=True).decode()
if content_type == "text/plain":
# print only text email parts
print(body)
if content_type == "text/html":
# if it's HTML, create a new HTML file and open it in browser
folder_name = clean(subject)
if not os.path.isdir(folder_name):
# make a folder for this email (named after the subject)
os.mkdir(folder_name)
filename = "index.html"
filepath = os.path.join(folder_name, filename)
# write the file
open(filepath, "w").write(body)
# open in the default browser
webbrowser.open(filepath)
print("="*100)
# close the connection and logout
imap.close()
imap.logout()
Как удалить электронные письма в Python?
Для того чтобы удалять электронные письма, можно использовать вот этот код:
import imaplib
import email
from email.header import decode_header
# учетные данные
username = ""
password = "password"
# create an IMAP4 class with SSL
imap = imaplib.IMAP4_SSL("imap.gmail.com")
# authenticate
imap.login(username, password)
# select the mailbox I want to delete in
# if you want SPAM, use imap.select("SPAM") instead
imap.select("INBOX")
# поиск определенных писем по отправителю
status, messages = imap.search(None, "FROM", "")
# преобразовать сообщения в список адресов электронной почты
messages = messages[0].split(b' ')
try:
for mail in messages:
_, msg = imap.fetch(mail, "(RFC822)")
# вы можете удалить цикл for для повышения производительности, если у вас длинный список писем
# потому что он предназначен только для печати SUBJECT целевого электронного письма, которое нужно удалить
for response in msg:
if isinstance(response, tuple):
msg = email.message_from_bytes(response[1])
# расшифровать тему письма
subject = decode_header(msg["Subject"])[0][0]
if isinstance(subject, bytes):
# if it's a bytes type, decode to str
subject = subject.decode()
print("Deleting", subject)
# отметить письмо как удаленное
imap.store(mail, "+FLAGS", "\\Deleted")
except:
print("Все удаленно")
# навсегда удалить письма, помеченные как удаленные
# из выбранного почтового ящика (в данном случае INBOX)
imap.expunge()
# закрыть почтовый ящик
imap.close()
# выйти из аккаунта
imap.logout()
Как отправлять электронные письма с Python?
Для того чтобы отправлять электронные письма, можно использовать вот этот код:
import smtplib
from email import encoders
from email.mime.text import MIMEText
from email.mime.multipart import MIMEMultipart
from email.mime.base import MIMEBase
from bs4 import BeautifulSoup as bs
# ваши учетные данные
email = "uru07082000"
password = "password"
# электронная почта отправителя
FROM = ""
# адрес электронной почты получателя
TO = ""
# тема письма (тема)
subject = "Test"
# инициализируем сообщение, которое хотим отправить
msg = MIMEMultipart("alternative")
# установить адрес электронной почты отправителя
msg["From"] = FROM
# установить адрес электронной почты получателя
msg["To"] = TO
# задаем тему
msg["Subject"] = subject
# установить тело письма как HTML
html = """
Mail Python!
"""
# делаем текстовую версию HTML
text = bs(html, "html.parser").text
# прикрепить тело письма к почтовому сообщению
# сначала прикрепите текстовую версию
msg.attach(text_part)
msg.attach(html_part)
print(msg.as_string())
def send_mail(email, password, FROM, TO, msg):
# инициализировать SMTP-сервер
server = smtplib.SMTP("smtp.gmail.com", 587)
# подключиться к SMTP-серверу в режиме TLS (безопасный) и отправить EHLO
server.starttls()
# войти в учетную запись, используя учетные данные
server.login(email, password)
# отправить электронное письмо
server.sendmail(FROM, TO, msg.as_string())
# завершить сеанс SMTP
server.quit()
send_mail(email, password, FROM, TO, msg)
Также можно делать рассылки с помощью этого кода:
import smtplib
from email.mime.text import MIMEText
from email.mime.multipart import MIMEMultipart
from bs4 import BeautifulSoup as bs
to_list = ['', '']
def send_mail(email, password, FROM, TO, msg):
# инициализировать SMTP-сервер
server = smtplib.SMTP("smtp.gmail.com", 587)
# подключиться к SMTP-серверу в режиме TLS (безопасный) и отправить EHLO
server.starttls()
# войти в учетную запись, используя учетные данные
server.login(email, password)
# отправить электронное письмо
server.sendmail(FROM, TO, msg.as_string())
# завершить сеанс SMTP
server.quit()
for recipient in to_list:
# ваши учетные данные
email = ""
password = "password"
# электронная почта отправителя
FROM = ""
# адрес электронной почты получателя
TO = recipient
# тема письма (тема)
subject = "Прикол"
# инициализируем сообщение, которое хотим отправить
msg = MIMEMultipart("alternative")
# установить адрес электронной почты отправителя
msg["From"] = FROM
# установить адрес электронной почты получателя
msg["To"] = TO
# задаем тему
msg["Subject"] = subject
# установить тело письма как HTML
html = """
Рассылка - Пока!!!!!
"""
# делаем текстовую версию HTML
text = bs(html, "html.parser").text
text_part = MIMEText(text, "plain")
html_part = MIMEText(html, "html")
# прикрепить тело письма к почтовому сообщению
# сначала прикрепите текстовую версию
msg.attach(text_part)
msg.attach(html_part)
# отправить почту
send_mail(email, password, FROM, TO, msg)
Автор статьи : Кузнецова Полина Александровна
Статья освещает настройку Redis на Heroku и запуск веб-процесса, а так же рабочего процесса на одном dyno, обновляя промежуточную среду с помощью функции подсчета слов.
Перевод статьи выполнен качественно, без каких-либо замечаний. Все разделы статьи логически взаимосвязаны, а положения статьи подтверждены рабочими примерами кодов и ссылками на научные исследования. В ходе прочтения смысловых и грамматических ошибок не обнаружено. Ссылка на оригинальную статью есть. Имеется также правильное и приятное для чтения оформление самого перевода, где в самом начале идет название темы, а после оглавление, в котором отображается содержание статьи с ссылками на эти пункты. Само оформление кодов реализовано очень удобно для читателя: они заметны, их сразу видно в статье; имеется возможность копирования всего кода сразу; возможность открыть код в новом окне браузера. Все коды в переводе объяснены, а их отдельно взятые элементы выделены в тексте жирным шрифтом. Полина выполнила работу в необходимом объеме и в указанные сроки. Порекомендовал бы поставить оценку “отлично”.
Списки и кортежи являются самыми универсальными и полезными типами данных в Python. Вы найдете их практически в каждой нетривиальной программе Python. Читать далее «Списки и кортежи в Python»
В своем простейшем виде фронтенд фреймворк – это просто полезная коллекция компонентов CSS, HTML и JavaScript, которые могут быть использованы в наших с Вами проектах. Некоторые из них будут супер легкими с минимальным набором компонентов, другие будут потяжелее, но с полным комплектом мыслимых и немыслимых компонентов. Конечно, выбор будет зависеть от размера и типа проекта. Поэтому выбирайте с умом!
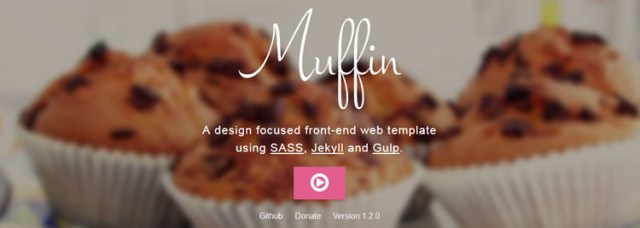
Muffin
По сути, это не фреймворк, Muffin – сосредоточенный на дизайне веб-шаблон фронтенда для рeйтинга статических сайтов с помощью SASS and Jekyll. Muffin использует общие методы Bootstrap, Boilerplate, inuit.css и других библиотек, для чтобы Вам было приятней писать код !
Cравнение Muffin c другими Фреймворками!
Для того, чтобы сделать выводы о популярности этого фреймворка, было принято решение создать сравнительную таблицу, расположенную ниже.Muffin, был сравнен с такими фреймворками как – Jango и CherryPy по следующим критериям:
• Группа фреймворков: Full stack или Micro-framework.
• Звёзды Github: общее количество звезд проекта, выставленных пользователям.
• Релизы Github: количество релизов каждого проекта, что отражает активность работы над проектом и его зрелость.
• Fork-и Github: количество, сделанных копий каждого проекта, что показывает популярность использования проекта в собственных работах.
• Вопросы Stack-overflow: количество вопросов, заданных по определенной теме.
• Вакансии: количество вакансий, связанных с технологиями или ИТ компетенциями.
Название фреймворка
Группа фреймворка
Звезды на Github
Релизы на Github
Fork-и на Github
Вопросы на stackoverflow
Вакансии
Muffin
Asyncio
874
216
615
4639
2
Django
Full
46 528
275
20 400
217 300
679
CherryPy
Micro
1 130
127
279
1 300
3
Вывод:
Я сделал вывод из проделанной работы! Можно с уверенностью сказать что Muffin не пользуется обширной популярностью,к сожалению! Но если вам хочется как можно приятнее писать код , то Muffin вам обязательно поможет!
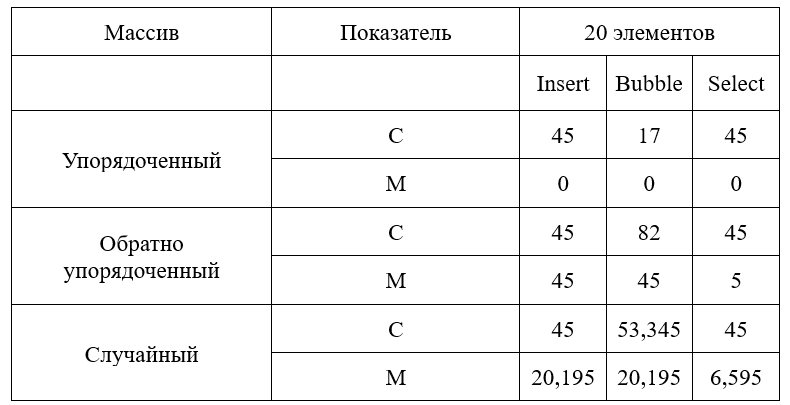
В данной части курсовой работы была написана программа, которая определяет эффективность трех алгоритмов сортировки (Сортировка включением, Обменная сортировка, Сортировка выбором). Каждый алгоритм сортировки оформлен в виде функции, которые подключены к основной программе.
Проведено 9 опытов (3 метода х 3 реализации одномерного массива), в каждом из которых определено два числа (С - Количество сравнений М - Количество перемещений), но в третьем случае, случайного массива, в отличие от двух первых, сравнительный анализ алгоритмов возможен только по средним значениям. Для этого проведено серия опытов, желательно, 1500 для каждого алгоритма.
Итоги
Исходя из проделанной работы можно сделать вывод. Самым эффективным методом сортировки для массива является метод "Select"
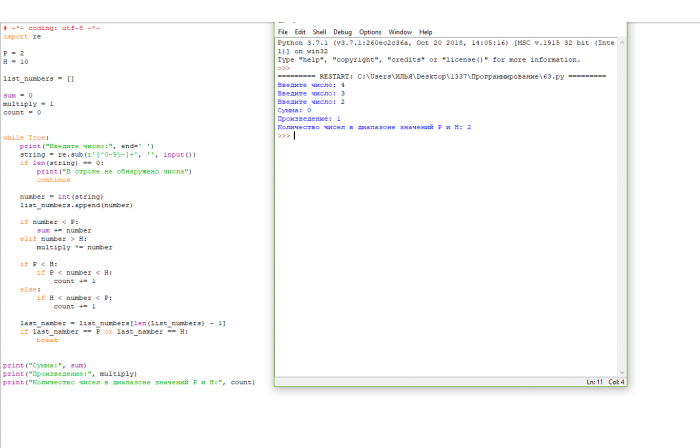
Даны число P и число H. Определить сумму чисел меньше P, произведение чисел больше H и количество чисел в диапазоне значений P и H. При вводе числа равного P или H, закончить работу.
Последовательно вводятся числа. Определить сумму чисел с нечётными номерами и произведение чисел с чётными номерами (по порядку ввода). Подсчитать количество слагаемых и количество сомножителей. При вводе числа 55555 закончить работу.
Заданы M строк символов, которые вводятся с клавиатуры. Каждая строка представляет собой последовательность символов, включающих в себя вопросительные знаки. Заменить в каждой строке все имеющиеся вопросительные знаки звёздочками.