Если необходимо обнаружить поддомены конкретного Web - сайта, то можно воспользоваться следующей программой. Используется метод полного перебора, будут проверяться все общие имена поддоменов этого конкретного домена, если будет получен ответ от сервера, то это означает, что поддомен существует. Был составлен список поддоменов для сканирования и помещен в файл «subdomains.txt».
#import requests
# домен для поиска поддоменов
domain = "susu.ru"
# читать все поддомены
file = open("D:\Надя\Костерин\Поддомены\subdomains.txt")
# прочитать весь контент
content = file.read()
# разделить на новые строки
subdomains = content.splitlines()
# список обнаруженных поддоменов
discovered_subdomains = []
for subdomain in subdomains:
# создать URL
url = f"http://{subdomain}.{domain}"
try:
# если возникает ОШИБКА, значит, субдомен не существует
requests.get(url)
except requests.ConnectionError:
# если поддомена не существует, просто передать, ничего не выводить
pass
else:
print("[+] Обнаружен поддомен:", url)
# добавляем обнаруженный поддомен в наш список
discovered_subdomains.append(url)
# сохраняем обнаруженные поддомены в файл
with open("discovered_subdomains.txt", "w") as f:
for subdomain in discovered_subdomains:
print(subdomain, file=f)
В результате работы программы были получены следующие результаты для домена susu.ru :
"D:\Program Files (x86)\Microsoft Visual Studio\Shared\Python37_64\python.exe" D:/Регина/Костерин/Поддомены/Сканерподдоменов.py
[+] Обнаружен поддомен: http://mail.susu.ru
[+] Обнаружен поддомен: http://test.susu.ru
[+] Обнаружен поддомен: http://lists.susu.ru
[+] Обнаружен поддомен: http://support.susu.ru
[+] Обнаружен поддомен: http://wiki.susu.ru
[+] Обнаружен поддомен: http://media.susu.ru
[+] Обнаружен поддомен: http://my.susu.ru
[+] Обнаружен поддомен: http://sites.susu.ru
[+] Обнаружен поддомен: http://info.susu.ru
[+] Обнаружен поддомен: http://office.susu.ru
Process finished with exit code 0
Для того чтобы читать электронные письма, можно использовать вот этот код:
import imaplib
import email
from email.header import decode_header
import webbrowser
import os
# учетные данные
username = ""
password = "password"
def clean(text):
# чистый текст для создания папки
return "".join(c if c.isalnum() else "_" for c in text)
# create an IMAP4 class with SSL
imap = imaplib.IMAP4_SSL("imap.gmail.com")
# authenticate
imap.login(username, password)
status, messages = imap.select("INBOX")
# количество популярных писем для получения
N = 1
# общее количество писем
messages = int(messages[0])
for i in range(messages, messages-N, -1):
# fetch the email message by ID
res, msg = imap.fetch(str(i), "(RFC822)")
for response in msg:
if isinstance(response, tuple):
# parse a bytes email into a message object
msg = email.message_from_bytes(response[1])
# decode the email subject
subject, encoding = decode_header(msg["Subject"])[0]
if isinstance(subject, bytes):
# if it's a bytes, decode to str
subject = subject.decode(encoding)
# decode email sender
From, encoding = decode_header(msg.get("From"))[0]
if isinstance(From, bytes):
From = From.decode(encoding)
print("Subject:", subject)
print("From:", From)
# if the email message is multipart
if msg.is_multipart():
# iterate over email parts
for part in msg.walk():
# extract content type of email
content_type = part.get_content_type()
content_disposition = str(part.get("Content-Disposition"))
try:
# get the email body
body = part.get_payload(decode=True).decode()
except:
pass
if content_type == "text/plain" and "attachment" not in content_disposition:
# print text/plain emails and skip attachments
print(body)
elif "attachment" in content_disposition:
# download attachment
filename = part.get_filename()
if filename:
folder_name = clean(subject)
if not os.path.isdir(folder_name):
# make a folder for this email (named after the subject)
os.mkdir(folder_name)
filepath = os.path.join(folder_name, filename)
# download attachment and save it
open(filepath, "wb").write(part.get_payload(decode=True))
else:
# extract content type of email
content_type = msg.get_content_type()
# get the email body
body = msg.get_payload(decode=True).decode()
if content_type == "text/plain":
# print only text email parts
print(body)
if content_type == "text/html":
# if it's HTML, create a new HTML file and open it in browser
folder_name = clean(subject)
if not os.path.isdir(folder_name):
# make a folder for this email (named after the subject)
os.mkdir(folder_name)
filename = "index.html"
filepath = os.path.join(folder_name, filename)
# write the file
open(filepath, "w").write(body)
# open in the default browser
webbrowser.open(filepath)
print("="*100)
# close the connection and logout
imap.close()
imap.logout()
Как удалить электронные письма в Python?
Для того чтобы удалять электронные письма, можно использовать вот этот код:
import imaplib
import email
from email.header import decode_header
# учетные данные
username = ""
password = "password"
# create an IMAP4 class with SSL
imap = imaplib.IMAP4_SSL("imap.gmail.com")
# authenticate
imap.login(username, password)
# select the mailbox I want to delete in
# if you want SPAM, use imap.select("SPAM") instead
imap.select("INBOX")
# поиск определенных писем по отправителю
status, messages = imap.search(None, "FROM", "")
# преобразовать сообщения в список адресов электронной почты
messages = messages[0].split(b' ')
try:
for mail in messages:
_, msg = imap.fetch(mail, "(RFC822)")
# вы можете удалить цикл for для повышения производительности, если у вас длинный список писем
# потому что он предназначен только для печати SUBJECT целевого электронного письма, которое нужно удалить
for response in msg:
if isinstance(response, tuple):
msg = email.message_from_bytes(response[1])
# расшифровать тему письма
subject = decode_header(msg["Subject"])[0][0]
if isinstance(subject, bytes):
# if it's a bytes type, decode to str
subject = subject.decode()
print("Deleting", subject)
# отметить письмо как удаленное
imap.store(mail, "+FLAGS", "\\Deleted")
except:
print("Все удаленно")
# навсегда удалить письма, помеченные как удаленные
# из выбранного почтового ящика (в данном случае INBOX)
imap.expunge()
# закрыть почтовый ящик
imap.close()
# выйти из аккаунта
imap.logout()
Как отправлять электронные письма с Python?
Для того чтобы отправлять электронные письма, можно использовать вот этот код:
import smtplib
from email import encoders
from email.mime.text import MIMEText
from email.mime.multipart import MIMEMultipart
from email.mime.base import MIMEBase
from bs4 import BeautifulSoup as bs
# ваши учетные данные
email = "uru07082000"
password = "password"
# электронная почта отправителя
FROM = ""
# адрес электронной почты получателя
TO = ""
# тема письма (тема)
subject = "Test"
# инициализируем сообщение, которое хотим отправить
msg = MIMEMultipart("alternative")
# установить адрес электронной почты отправителя
msg["From"] = FROM
# установить адрес электронной почты получателя
msg["To"] = TO
# задаем тему
msg["Subject"] = subject
# установить тело письма как HTML
html = """
Mail Python!
"""
# делаем текстовую версию HTML
text = bs(html, "html.parser").text
text_part = MIMEText(text, "plain")
html_part = MIMEText(html, "html")
# прикрепить тело письма к почтовому сообщению
# сначала прикрепите текстовую версию
msg.attach(text_part)
msg.attach(html_part)
print(msg.as_string())
def send_mail(email, password, FROM, TO, msg):
# инициализировать SMTP-сервер
server = smtplib.SMTP("smtp.gmail.com", 587)
# подключиться к SMTP-серверу в режиме TLS (безопасный) и отправить EHLO
server.starttls()
# войти в учетную запись, используя учетные данные
server.login(email, password)
# отправить электронное письмо
server.sendmail(FROM, TO, msg.as_string())
# завершить сеанс SMTP
server.quit()
send_mail(email, password, FROM, TO, msg)
Также можно делать рассылки с помощью этого кода:
import smtplib
from email.mime.text import MIMEText
from email.mime.multipart import MIMEMultipart
from bs4 import BeautifulSoup as bs
to_list = ['', '']
def send_mail(email, password, FROM, TO, msg):
# инициализировать SMTP-сервер
server = smtplib.SMTP("smtp.gmail.com", 587)
# подключиться к SMTP-серверу в режиме TLS (безопасный) и отправить EHLO
server.starttls()
# войти в учетную запись, используя учетные данные
server.login(email, password)
# отправить электронное письмо
server.sendmail(FROM, TO, msg.as_string())
# завершить сеанс SMTP
server.quit()
for recipient in to_list:
# ваши учетные данные
email = ""
password = "password"
# электронная почта отправителя
FROM = ""
# адрес электронной почты получателя
TO = recipient
# тема письма (тема)
subject = "Прикол"
# инициализируем сообщение, которое хотим отправить
msg = MIMEMultipart("alternative")
# установить адрес электронной почты отправителя
msg["From"] = FROM
# установить адрес электронной почты получателя
msg["To"] = TO
# задаем тему
msg["Subject"] = subject
# установить тело письма как HTML
html = """
Рассылка - Пока!!!!!
"""
# делаем текстовую версию HTML
text = bs(html, "html.parser").text
text_part = MIMEText(text, "plain")
html_part = MIMEText(html, "html")
# прикрепить тело письма к почтовому сообщению
# сначала прикрепите текстовую версию
msg.attach(text_part)
msg.attach(html_part)
# отправить почту
send_mail(email, password, FROM, TO, msg)
Автоматизация процесса входа на какой-либо веб-сайт, используя программу, написанную на Python, очень удобна и практична в эксплуатации. Реализовывается это благодаря библиотеке Selenium WebDriver. Selenium WebDriver — это библиотека для управления браузером, которая поддерживает все основные браузеры и доступна для разных языков программирования, включая Python. И в данной работе я бы хотел использовать ее для автоматизированного входа на GitHub.
Первым делом, что нам необходимо сделать – это установить Selenium для Python, использую команду: pip3 install selenium. После этого, понадобится установить специфичный драйвер для браузера, которым мы хотим управлять. Лично я, буду использовать ChromeDriver, но вы можете использовать любой другой. Далее, необходимо открыть новый скрипт Python, инициализировать WebDriver и ввести свои учетные данные от GitHub:
from selenium import webdriver
from selenium.webdriver.support.ui import WebDriverWait
# Github credentials
username = "username"
password = "password"
# initialize the Chrome driver
driver = webdriver.Chrome("chromedriver")
После того, как мы загрузили и разархивировали драйвер, необходимо будет его поместить в текущий каталог, то есть, скачанный мною chromedriver.exe я помещаю в папку с проектом. Именно поэтому, я просто передаю его имя конструктору.
Поскольку мы заинтересованы в автоматизации входа в систему GitHub, то перейдем на страницу входа в Github и посмотрим на неё через кнопку f12 для того, чтобы найти её HTML элементы, а именно: идентификатор полей ввода логина и пароля, а также имя кнопки входа, необходимые для получения этих элементов в коде и их запрограммирования. Обратите внимание, что поле ввода имени пользователя/адреса электронной почты имеет id поля login_field, где поле ввода пароля имеет id password. Также кнопка отправки имеет имя commit. И приведенный ниже код переходит на страницу входа в Github, извлекает эти элементы, заполняет учетные данные и нажимает кнопку:
# перейти на страницу входа в github
driver.get("https://github.com/login")
# найти поле имени пользователя / электронной почты и отправить само имя пользователя в поле ввода
driver.find_element_by_id("login_field").send_keys(username)
# найти поле ввода пароля и также вставить пароль
driver.find_element_by_id("password").send_keys(password)
# нажмите кнопку входа в систему
driver.find_element_by_name("commit").click()
В данном коде, функция find_element_by_id() извлекает HTML элемент по его идентификатору, а метод send_keys() имитирует нажатие клавиш. Приведенный выше код заставит Chrome ввести электронное письмо и пароль, а затем нажать кнопку «Sign in».
Следующее, что нужно сделать, это определить, был ли наш вход в систему успешным. Для этого есть масса способов, но здесь мы попытаемся обнаружить ошибку при входе в систему. С помощью все той же консоли, которая вызывается клавишей f12, мы увидим, что при непрвильном вводе учетных данных, появляется новый элемент div HTML с классом «flash-error», который имеет текст «Incorrect username or password» («Неправильное имя пользователя или пароль»). Приведенный ниже код отвечает за ожидание загрузки страницы после входа в систему с помощью WebDriverWait() и проверяет наличие ошибки:
# ждем завершения состояния готовности
WebDriverWait(driver=driver, timeout=10).until(
lambda x: x.execute_script("return document.readyState === 'complete'")
)
error_message = "Incorrect username or password."
# получаем ошибки (если есть)
errors = driver.find_elements_by_class_name("flash-error")
# при необходимости распечатать ошибки
# для e в ошибках:
# print(e.text)
# если мы находим это сообщение об ошибке в составе error, значит вход не выполнен
if any(error_message in e.text for e in errors):
print("[!] Login failed")
else:
print("[+] Login successful")
Тут мы используем WebDriverWait, чтобы дождаться завершения загрузки документа, метод execute_script() выполняет Javascript в браузере, код JS возвращает document.readyState === 'complete' возвращает True, если всё хорошо и False в противном случае.
В результате всех этих действий мы получаем очень удобную программу, которая упрощает нам жизнь. Например, мы написали какую-либо программу на Python и хотим ее выгрузить на наш GitHub. И раньше, чтобы это сделать, необходимо было заходить в браузер, переходить на сайт, вводить свои учетные данные и после этого уже загружать свой новый проект в репозиторий. Теперь же, достаточно просто запустить эту программу, и она все основные действия сделает за вас, вам останется лишь загрузить свой проект.
Статья Data Migrations освещает:
1)Определение миграции данных
2)Примеры
Актуальность статьи обусловлена вопросом: Что нужно постоянно обновлять, чтобы избежать рассинхронизации версий БД и приложений?
Миграции в основном предназначены для поддержания актуальной модели данных вашей базы данных, но база данных - это больше, чем просто модель данных. В частности, это большой набор данных. Таким образом, любое обсуждение миграции базы данных было бы неполным, если бы мы не говорили о миграции данных.
Миграция данных используется в нескольких сценариях. Два очень популярных:
Когда вы хотите загрузить «системные данные», от которых зависит успешная работа вашего приложения.
Когда изменение модели данных вызывает необходимость изменить существующие данные.
В процессе выполнения и сдачи окончательного варианта перевода статьи, были исправлены замечания, которые Екатерина исправила в указанное время. Перевод статьи выполнен качественно. Так же Екатерина выполнила кликабельное оглавление, с возможностью перехода на нужные разделы статьи. Перевод статьи выполнен верно и легко читаемо. Кроме этого были проверены коды, которые перенесены с оригинала верно, работают отлично. В конце статьи приведена ссылка на оригинал. Екатерина выполнила работу качественно и своевременно, и не смотря на ряд незначительных замечаний, которые были исправлены во время, работа оценивается на отлично.
Разработка сайта должна начинаться с технического задания. А что должно включать это техническое задание?
Техническое задание должно описывать структуру сайта, для кого он предназначен и какой функционал должен на нем присутствовать. Это интернет-магазин, это каталог с опцией заказа, это сайт для лидогенерации, для регистрации на какое-либо мероприятие. Весь функционал, что нужно для того, чтобы сайт был полноценным участником бизнес-процессов компании, должен быть описан максимально подробно. Сайт – такой продукт, который, требования к которому формируются по ходу разработки. Именно поэтому в техническое задание необходимо вынести критические какие-то вещи, ради которых сайт создается. А все остальное можно либо отнести на доработке, либо подойти достаточно гибко к процессу разработки, когда заказчик принимает участие в ходе всей разработки. Читать далее →
Итерация — выполнение одного и того же блока кода снова и снова. Конструкция программирования, реализующая итерацию, называется циклом.
В программировании есть два типа итераций: неопределенные и определенные:
При неопределенной итерации количество выполнений цикла заранее не указывается. Назначенный блок выполняется повторно, пока выполняется какое‑либо условие.
При определенной итерации, в момент запуска цикла указывается количество раз выполнения указанного блока.
Что может быть лучше гигантской рептилии? Его ядовитый лучший друг! Vibora расшифровывается как гадюка на португальском языке и представляет собой асинхронный клиент-серверный фреймворк, который стремится стать самым быстрым Python HTTP-клиент-серверным фреймворком!
Vibora является быстрым, асинхронным и, как называют его создатели, элегантным клиент-серверным фреймворком Python 3.6+. Фреймворк был спроектирован и создан с нуля, чтобы быть эффективным и предлагать отличную производительность, его встроенные функции основаны на многочисленных известных библиотеках, таких как jinja2, marshmallow, websockets aaugustin, werkzeug и других. Vibora является полностью асинхронной, потому что веб-API часто основаны на вводе-выводе, и именно в этом и заключается асинхронная архитектура.
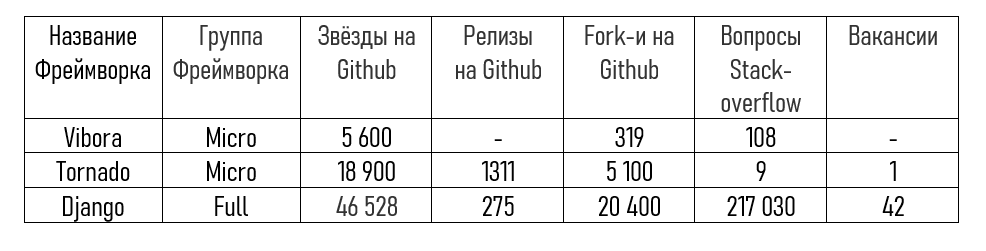
Сравнительная таблица
Vibora был сравнен с такими фреймворками как Jango и Tornado по следующим критериям:
• Группа фреймворков: Full stack или Micro-framework.
• Звёзды Github: общее количество звезд проекта, выставленных пользователям.
• Релизы Github: количество релизов каждого проекта, что отражает активность работы над проектом и его зрелость.
• Fork-и Github: количество, сделанных копий каждого проекта, что показывает популярность использования проекта в собственных работах.
• Вопросы Stack-overflow: количество вопросов, заданных по определенной теме.
• Вакансии: количество вакансий, связанных с технологиями или ИТ компетенциями.
Вывод
Vibora активно работает на GitHub, и его тесты показывают, что платформа постоянно набирает обороты. Его цель - стать самым быстрым Python HTTP клиент / серверным фреймворком и предоставлять приятные и современные функции разработки.
Однако следует отметить, что Vibora еще далека от завершения. Хотя уже предлагается список привлекательных функций, он все еще находится на ранней стадии разработки.
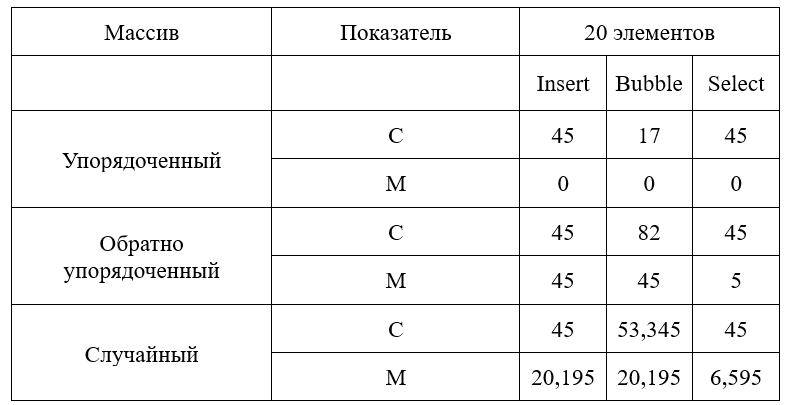
Для проведения исследования были выбраны следующие алгоритмы сортировки:
Insertion sort
Сортировка включением – алгоритм сортирует массив по мере прохождения по его элементам. На каждой итерации берется элемент и сравнивается с каждым элементом в уже отсортированной части массива, таким образом находя «свое место», после чего элемент вставляется на свою позицию. Так происходит до тех пор, пока алгоритм не пройдет по всему массиву. На выходе получим отсортированный массив. Сложность данного алгоритма равна O(n^2).
Selection sort
Сортировка выбором – суть алгоритма заключается в проходе по массиву от начала до конца в поиске минимального элемента массива и перемещении его в начало. Сложность такого алгоритма O(n2).
Bubble sort
Сортировка пузырьком– данный алгоритм меняет местами два соседних элемента, если первый элемент массива больше второго. Так происходит до тех пор, пока алгоритм не обменяет местами все неотсортированные элементы. Сложность данного алгоритма сортировки равна O(n^2).
Было проведено 9 опытов (3 метода х 3 реализации одномерного массива), в каждом из которых определено два числа (С - Количество сравнений М - Количество перемещений), но в третьем случае, случайного массива, в отличие от двух первых, сравнительный анализ алгоритмов возможен только по средним значениям.
Исходя из проделанной работы можно сделать вывод. Самым эффективным методом сортировки для массива является метод "Select"
С 1 по 2 декабря прошёл ИТ-марафон с выездом на базу отдыха "Наука" в село Непряхино. Участниками марафона были студенты с различных IT-кафедр (в том числе нашей) и представители ИТ-компаний. Марафон состоял из представления докладов, таких как "Карьера в ИТ, быстрый старт","Миграция в ИТ", "Экорадар", "Эти три волшебные буквы-CMS", "Тестирование Web", "Инструменты веб-разработчика". Проводились различные конкурсы, направленные на командную работу, рандомное формирование команд предоставило возможность познакомиться с другими участниками марафона. Очень интересная программа марафона не позволила заскучать, а завершился этот насыщенный день гитарником и дискотекой.