Проведение анализа информационных потребностей предприятия по подразделениям. Подготовка по результатам анализа отчета с указанием соответствующих рекомендаций.
07.07.2021
Приступила к написанию модели AS-IS. Учувствовала в процессе производства готовой продукции предприятия.
06.07.2021
Продолжила сбор информации для построения и анализа бизнес-процессов организации.
05.07.2021
Работала в программе Microsoft Word,помогала руководителю набирать документы.
02.07.2021
Приступила к сбору информации для построения, анализа и предложения своих идей по автоматизации бизнес-процессов.
01.07.2021
Сбор информации для построения и анализа Бизнес-Процессов организации, а так жен построение модели idef0
30.06.2021
Сегодня второй день производственной практики и я изучала основные документы, которые регламентируют деятельность IT-специалиста, и должностные инструкции. Ознакомилась с особенностями документооборота в рамках своей специальности.
Изучила оборудования и информационную структуру предприятия. Ознакомилась с технической деятельностью организации. Оказала помощь в установке антивирусной защиты информационной сети.
29.06.2021
Сегодня прошел первый день моей производственной практики в ООО «Челябинский завод полиамидных изделий».
Я ознакомилась с организационной структурой предприятия и ключевыми видами деятельности организации.
Изучение внутреннего распорядка:
Я ознакомилась с предприятием, познакомилась с обслуживающим персоналом, мне провели экскурсию по самому предприятию, ознакомилась с инструктажем по технике безопасности. Руководитель предприятия объяснил все мои обязанности, которые нужно выполнять в период практики.
Описательная статистика на Python (Центральные метрики и метрики оценки вариативности)
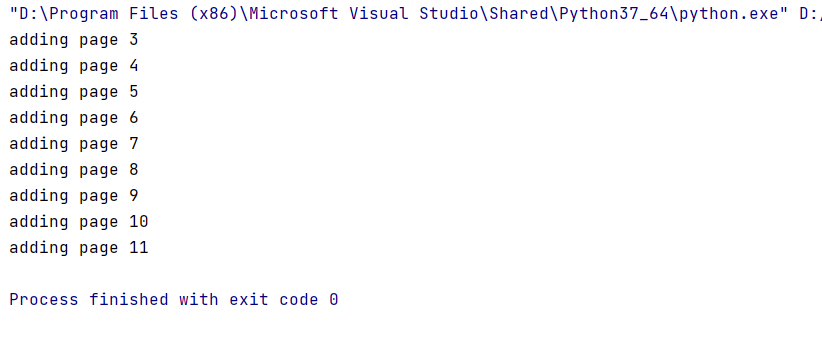
Для изучения статистики загружаем библиотеки: math, numpy, pandas, statistics, scipy.stats. Посмотрим, каким образом можно рассчитать центральные метрики, средневзвешенное, гармоническое среднее, среднее геометрическое, медиану, моду, дисперсию, среднеквадратичное отклонение, смещение, процентили, диапазон. Программный код для расчёта данных показателей приведён ниже.
#
import math
import statistics
import numpy as np
import scipy.stats
import pandas as pd
print("Исходные данные")
x = [8.0, 1, 2.5, 4, 28.0]
x_with_nan = [8.0, 1, 2.5, math.nan, 4, 28.0]
y, y_with_nan = np.array(x), np.array(x_with_nan)
z, z_with_nan = pd.Series(x), pd.Series(x_with_nan)
print(y)
print(y_with_nan)
print(z)
print(z_with_nan)
# Среднее значение
print("Среднее значение")
mean_=sum(x)/len(x)
print(mean_)
mean_=statistics.mean(x)
print(mean_)
m=np.nanmean(y_with_nan)
print(m)
# Средневзвешенное значение
print("Средневзвешенное значение")
x = [8.0, 1, 2.5, 4, 28.0]
w = [0.1, 0.2, 0.3, 0.25, 0.15]
wmean = sum(w[i] * x[i] for i in range(len(x))) / sum(w)
print(wmean)
wmean = sum(x_ * w_ for (x_, w_) in zip(x, w)) / sum(w)
print(wmean)
# Средневзвешенное значение, использование массивов Numpy и Pandas
x = [8.0, 1, 2.5, 4, 28.0]
y, z, w = np.array(x), pd.Series(x), np.array(w)
wmean = np.average(y, weights=w)
print(wmean)
wmean = np.average(z, weights=w)
print(wmean)
# Гармоническое среднее
print("Гармоническое среднее")
hmean = len(x) / sum(1 / item for item in x)
print(hmean)
hmean==scipy.stats.hmean(y)
print(hmean)
# Среднее геометрическое
print("Среднее геометрическое")
gmean = 1
for item in x:
gmean *= item
gmean **= 1 / len(x)
print(gmean)
# Медиана
print("Медиана")
n = len(x)
if n % 2:
median_ = sorted(x)[round(0.5*(n-1))]
else:
x_ord, index = sorted(x), round(0.5 * n)
median_ = 0.5 * (x_ord[index-1] + x_ord[index])
print(median_)
print(z.median())
print(z_with_nan.median())
# Медиана
u = [2, 3, 2, 8, 12]
mode_ = max((u.count(item), item) for item in set(u))[1]
print(mode_)
# Дисперсия
print("Дисперсия")
n = len(x)
mean_ = sum(x) / n
var_ = sum((item - mean_)**2 for item in x) / (n - 1)
print(var_)
# Среднеквадратическое отклонение
print("Среднеквадратическое отклонение")
std_ = var_ ** 0.5
print(std_)
std_=np.std(y, ddof=1)
print(std_)
# Смещение
print("Смещение")
y, y_with_nan = np.array(x), np.array(x_with_nan)
print(scipy.stats.skew(y, bias=False))
print(scipy.stats.skew(y_with_nan, bias=False))
# Процентили
print("Процентили")
y = np.array(x)
print(np.percentile(y, 5))
print(np.percentile(y, 95))
# Диапазон
print("Диапазон")
print(np.amax(y) - np.amin(y))
print(np.nanmax(y_with_nan) - np.nanmin(y_with_nan))
print(y.max() - y.min())
print(z.max() - z.min())
print(z_with_nan.max() - z_with_nan.min())
Результат работы программы представлен ниже.
Работа с PDF файлами
Для разбиения отдельного pdf документа на страницы воспользуемся следующей программой
# from PyPDF2 import PdfFileReader, PdfFileWriter
pdf_document = "D:\Регина\Костерин\Поддомены\source\Формула включений и исключений.pdf"
pdf = PdfFileReader(pdf_document)
for page in range(pdf.getNumPages()):
pdf_writer = PdfFileWriter()
current_page = pdf.getPage(page)
pdf_writer.addPage(current_page)
outputFilename = "dist/Форм_вкл_искл-page-{}.pdf".format(page + 1)
with open(outputFilename, "wb") as out:
pdf_writer.write(out)
print("created", outputFilename)
Результат представлен на следующем рисунке

# import fitz
filename = "D:\Регина\Костерин\Поддомены\source\Формула включений и исключений.pdf"
search_term = "множество"
pdf_document = fitz.open(filename)
for current_page in range(len(pdf_document)):
page = pdf_document.loadPage(current_page)
if page.searchFor(search_term):
print("%s найдено на странице %i" % (search_term, current_page+1))
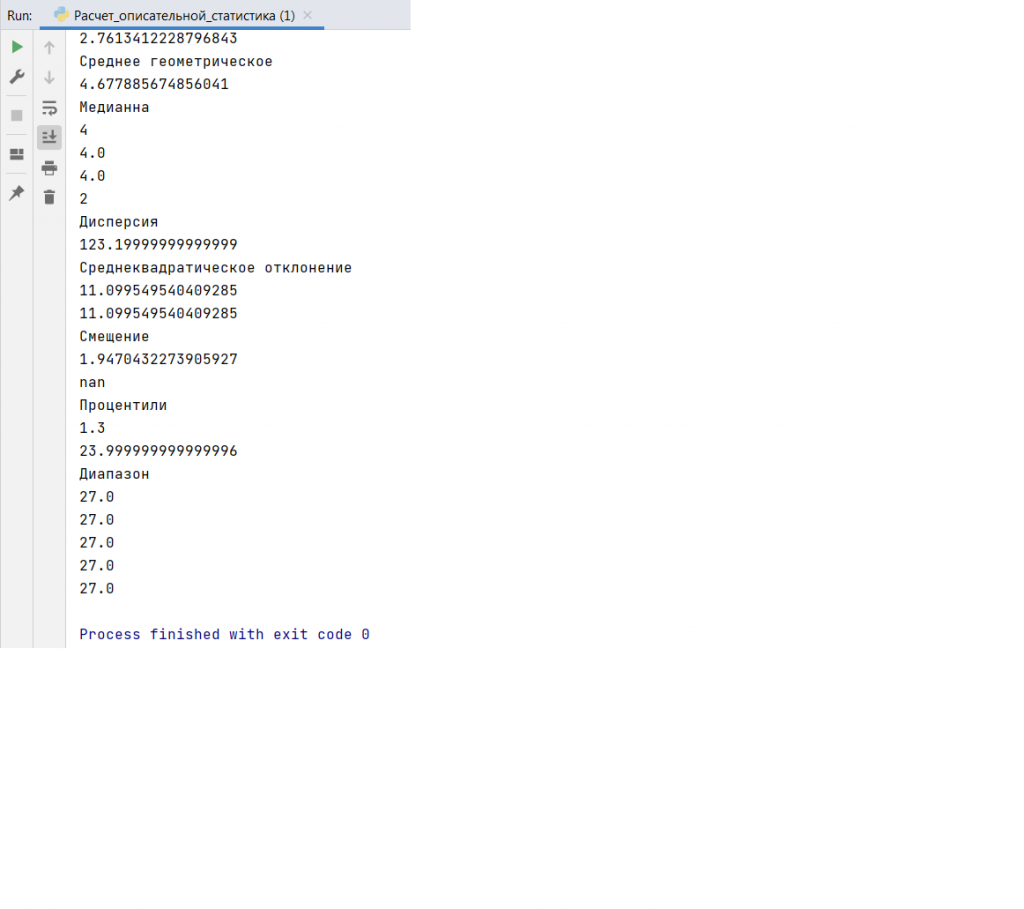
Осуществим поиск в документе Формула включения и исключения.pdf слова «множество».
Результат работы программы представлен ниже.
Добавление водяного знака с помощью PyPDF2
Добавим в pdf файл водяной знак «Черновик». Текст программы
# Добавление водяного знака в одностраничный PDF
import PyPDF2
input_file = "D:\Регина\Костерин\Поддомены\source\Задание 12.3.pdf"
output_file = "dist/Водяной_знак-page-drafted.pdf"
watermark_file = "source/Черновик.pdf"
with open(input_file, "rb") as filehandle_input:
# читать содержимое исходного файла
pdf = PyPDF2.PdfFileReader(filehandle_input)
with open(watermark_file, "rb") as filehandle_watermark:
# читать содержание водяного знака
watermark = PyPDF2.PdfFileReader(filehandle_watermark)
# получить первую страницу оригинального PDF
first_page = pdf.getPage(0)
# получить первую страницу водяного знака PDF
first_page_watermark = watermark.getPage(0)
# объединить две страницы
first_page.mergePage(first_page_watermark)
# создать объект записи PDF для выходного файла
pdf_writer = PyPDF2.PdfFileWriter()
# добавить страницу
pdf_writer.addPage(first_page)
with open(output_file, "wb") as filehandle_output:
# записать файл с водяными знаками в новый файл
pdf_writer.write(filehandle_output)
Результат работы программы

Удаление страниц с помощью pdfrw
Для удаления страниц необходимо установить библиотеку pdfrw. Текст программы приведен ниже.
# Удалите первые две страницы (титульный лист) из PDF
from pdfrw import PdfReader, PdfWriter
input_file = "D:\Регина\Костерин\Поддомены\source\Формула включений и исключений.pdf"
output_file = "dist/Удаление_страниц-page-drafted.pdf"
# Определить объекты чтения и записи
reader_input = PdfReader(input_file)
writer_output = PdfWriter()
# Перейти на страницу один за другим
for current_page in range(len(reader_input.pages)):
if current_page > 1:
writer_output.addpage(reader_input.pages[current_page])
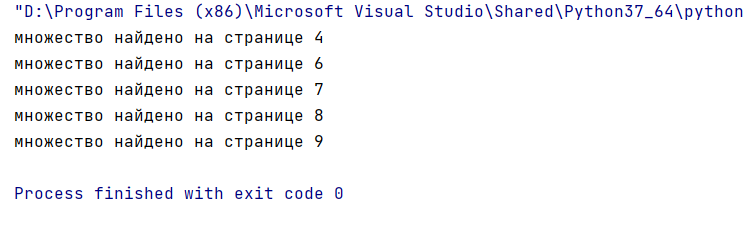
print("adding page %i" % (current_page + 1))
# Записать измененный контент на диск
writer_output.write(output_file)
Результат работы программы – сформирован новый файл, у которого вырезано 2 первые страницы.